CloudCanal RAG 实战|如何让问答机器人“智能”起来

在之前的文章中,我们介绍了如何使用 CloudCanal 和 Ollama 搭建全栈私有的 RAG ��问答服务,为企业级 RAG 应用提供了部署简单、安全可靠的解决方案。
最近,我们用这套方案,在 CloudCanal 官网上线了基于 知识库 的智能问答机器人。在发布前的测试过程中,却发现它似乎没有想象中那么“智能”,出现了答非所问、检索失焦、上下文理解有误等问题。
今天,我们将从 CloudCanal 官网问答机器人工程实践出发,深入分析传统 RAG 的瓶颈,并介绍 CloudCanal RAG 的针对性优化策略,展示如何构建一个真实可用的智能问答机器人。
传统 RAG 模式的问题
传统 RAG 流程简化如下:
- 原始文档 → 切分 → 向量化 → 存入向量数据库
- 用户提问 → 转换为查询向量 → 相似度检索 → 拼接上下文
- 构造 Prompt → 输入大模型 → 大模型推理并回答
这一流程看似十分合理,但实际操作时却会发现各种各样的问题:
数据处理粗糙,信息密度低
- 问题表现:直接对原始文档分块向量化,缺乏摘要、关键词、标签等关键元信息,导致向量无法精准表达文本核心内容。
- 典型场景:一篇关于各数据库版本支持情况的文档,若无摘要或关键词提炼,模型在检索时很难精准匹配到“版本支持”这一核心概念,导致召回失败。
知识库未分类,检索范围模糊
- 问题表现:将 FAQ、操作指南、更新日志等不同类型的文档混合存储在同一向量空间,未进行有效分类,容易导致检索范围定位错误。
- 典型场景:当用户提问“社区版支持哪些数据源?”时,系统可能因无法区分“产品功能”与“操作步骤”,错误地返回一篇关于“如何配置数据源连接”的指南,导致答非所问。
对话历史理解脱节,无法有效追溯
- 问题表现:简单拼接历史对话作为上下文,缺乏结构化标注,导致模型难以理解指代关系和焦点变化。
- 典型场景:用户先问“CloudCanal 免费吗?”,再问“Hana 呢?”。若缺乏上下文关联,模型可能将第二问理解为“什么是 Hana 数据库”,而不是“CloudCanal 对 Hana 数据源的支持在社区版是否免费”,无法准确理解用户问题的含义。
用户意图识别不清,向量检索偏离目标
- 问题表现:用户提问往往简洁甚至模糊,如果模型不能主动推断其真实意图,就会导致向量检索偏离甚至完全失效。
- 典型场景:对于一个孤立的问题“Hana 免费吗?”,若系统未能结合潜在上下文(如用户正在浏览 CloudCanal 文档)推断出“Hana”是指“CloudCanal 的数据源”,“免费”是指“社区版功能”,那么检索结果很可能跑偏,返回无关的 Hana 数据库介绍。
CloudCanal RAG:从“检索驱动”走向“理解驱动”
传统 RAG 模型的问题在于 检索驱动、理解缺失,而 CloudCanal RAG 对以上问题做了针对性的优化。
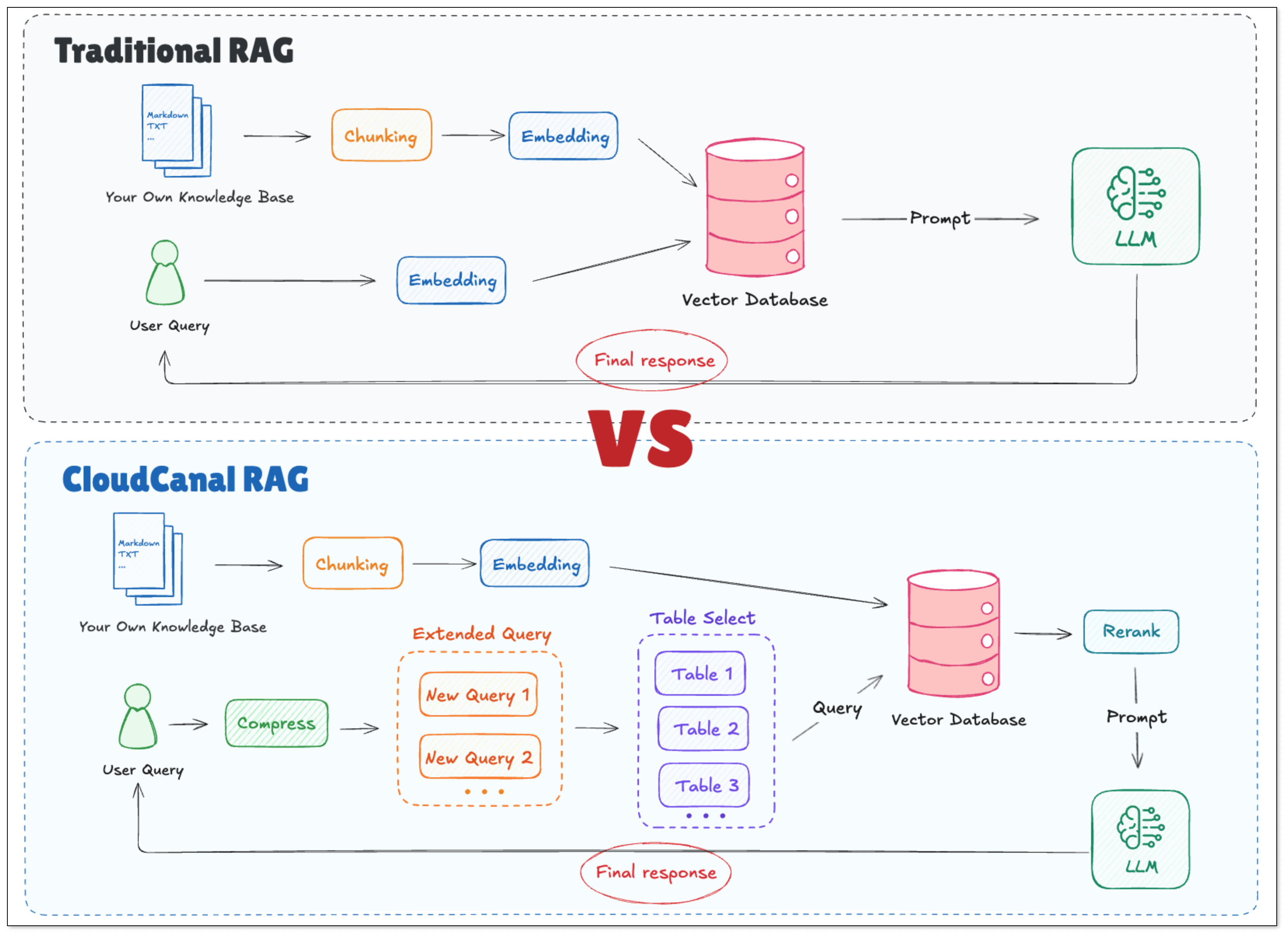
- 查询重构:将用户的模糊提问补全为精准问题;
- 查询扩展:生成多种等价问法,提升向量召回率;
- 查询路由:定位到最相关的知识模块,避免全库检索;
- 智能检索:并行将多种查询送入向量库,智能判断最优查询方式后,结合 分表召回 与 相关性重排(Rerank),过滤掉弱相关或无关内容;
- 结构化提示:用“权威事实+任务指令”框定模型输出,杜绝幻觉。
这些能力均内置于 CloudCanal,用户只需根据自身业务场景,稍作提示词调整,即可快速实现高精度、可落地的智能问答服务。
查询案例
下面通过一个真实的模糊查询案例来说明:
用户先问:CloudCanal 免费吗?
紧接着又问:Hana 支持吗?
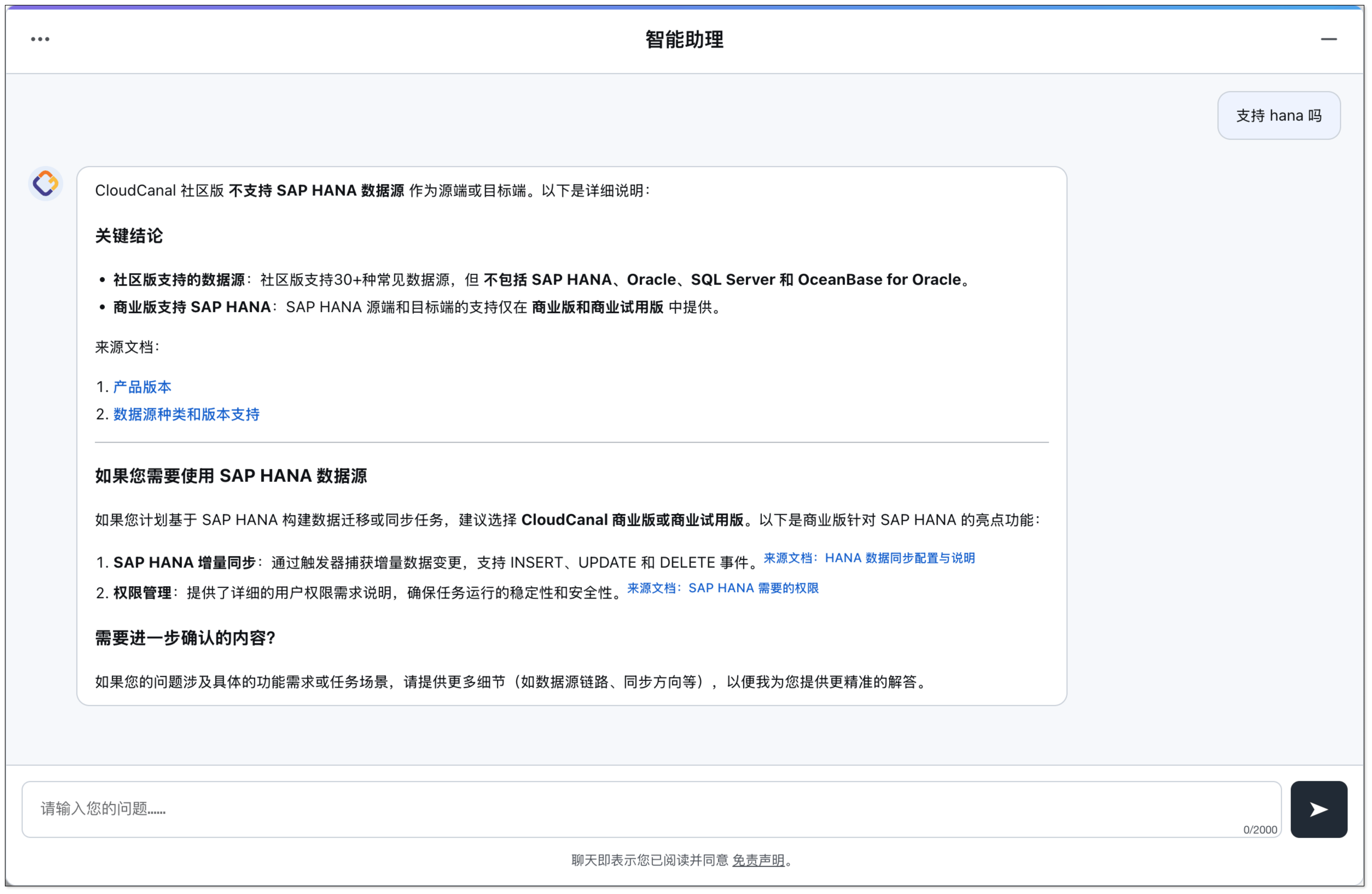
在传统 RAG 中,第二问往往被理解为“什么是 Hana?”,没有关联到对话历史中的“免费”,最终返回 Hana 数据库的相关介绍,而非“CloudCanal 社区版是否支持 SAP Hana 同步”。
在 CloudCanal RAG 中,整个执行流程如下:
第一步:查询重构
CloudCanal RAG 首先进行上下文分析,将模糊问题补全并精准化。
- 对话历史分析:检查到用户之前的对话提及了 社区版。
- 实体关联:Hana 识别为 SAP Hana 数据源,关联到核心内容 数据同步 和 社区版。
- 重构结果:Hana 支持吗?=> CloudCanal 的社区版是否支持免费同步 SAP Hana 数据源?
这一步彻底解决了传统 RAG 中 用户提问模糊、对话历史关联弱 的问题,为后续操作提供了清晰而精准的输入。
第二步:查询扩展
为了避免单一查询方式在向量检索中的失败,CloudCanal RAG 会将重构后的问题扩展为多个语义等价的问法,提升召回率。
- 社区版 CloudCanal 能连接 SAP Hana 吗?
- 使用 CloudCanal 社区版可以免费同步 Hana 数据吗?
- CloudCanal 社区版本包含对 SAP Hana 数据源的支持吗?
这一步有效应对了 数据处理粗糙 的问题,即使原始文档的措辞与用户提问不完全一致,也能精准命中相关知识。
第三步:查询路由
在进入具体向量检索前,CloudCanal RAG 会先判断当前问题应当查阅哪些类别的知识文档,以实现精确查询。
- 结合问题关键词和意图,判断是属于 FAQ、产品功能说明、价格策略、版本日志还是安装手册。
- 针对问题 “CloudCanal 社区版支持 SAP Hana 吗?”,系统判断属于“产品功能 + 产品定价”模块,只在相关知识表中查询。
这一步解决了 检索范围模糊 的问题,避免在全局知识库中进行大海捞针式的检索,提升了检索效率和准确性,防止不相关的知识干扰结果。
第四步:智能检索
将多个查询并行送入向量数据库,并对返回的结果进行智能筛选。
- 分表检索:从“产品功能”和“产品定价”知识表中召回初步匹配的片段。例如:
- 召回片段 1:...当前社区版默认支持 MySQL、PostgreSQL...
- 召回片段 2:...SAP Hana 数据源仅在商业版中开放...
- 召回片段 n:...
- 相关性重排 (Rerank):对所有召回片段进行细致评估,判断其与用户核心意图的关联度,剔除不相关或弱相关的部分。这一步至关重要,它能有效过滤掉噪声信息,确保最终用于生成答案的上下文是高度准确且相关的,避免大模型被无关信息误导。
这一环节确保了最终用于生成答案的上下文是高度准确且相关的。
第五步:结构化提示词生成
最后,构建一个高度结构化的提示词(用户可自定义),让大模型更好地推理。下面为简单的例子(实际会更复杂):
## 角色设定
“你是 CloudCanal 的官方技术支持助手。”
## 权威材料 (事实):
- “SAP Hana 数据源同步功能仅在 CloudCanal 企业版中支持。”
- “CloudCanal 社区版暂不包含对该数据源的支持。”
## 用户原始问题:
“CloudCanal 的 Hana 社区版免费吗?”
## 任务指令
“请基于权威材料,直接回答用户问题,并提供清晰指引。”
通过这种严谨的结构化方式,大模型的回答被严格限定在已验证的事实范围内,从根本上杜绝了“幻觉”的产生,保证了回答的权威性与可信度。
实际应用
构建好 CloudCanal RAG API 后,将其转化为面向用户的智能问答服务变得轻而易举。
通过整合 CloudCanal 自己开发的机器人应用,可以将 RAG 能力快速对接至多种企业协作平台,真正实现智能问答的落地应用。
上线后,CloudCanal 官网的智能问答机器人在多种复杂场景下均能基于文档准确解答用户问题,哪怕面对模糊表达、多轮追问或不规范术语,依然能提供清晰可信的答案。
总结
传统 RAG 偏向“被动检索”,而 CloudCanal RAG 通过一系列优化措施,让 RAG 应用走向 “主动理解 + 智能编排”。
- 从模糊提问中提炼用户真实意图
- 从上下文中构建精准查询路径
- 从海量信息中筛选最关键事实
它不仅能找答案,更能理解问题、规划流程、控制输出,为企业级 RAG 问答系统提供真正可落地的技术方案。