Oracle CDC 数据不一致排查:长事务与 LogMiner 上下文丢失问题

ORACLE 数据同步,数据不一致问题多种多样,其中在长事务场景里尤其容易出现。
一个事务可能跨越多轮 LogMiner 解析窗口;一条长 SQL 可能被拆成多段;一次 BLOB 更新可能先记录 locator,再分多次写入;事务最后还可能回滚。只要事务前半段的关键上下文丢了,目标端就可能无法还原源端真正提交后的结果。
本文围绕 Oracle LogMiner 增量同步中的长事务问题,重点讨论 3 个方面:
- 长事务为什么会影响 Oracle 同步准确性。
- BLOB、CSF 长 SQL、rollback 场景里,问题通常是怎么出现的。
- 如果要处理这类问题,同步链路通常需要具备哪些能力。
Oracle 长事务为什么会影响同步准确性
Oracle LogMiner 做增量同步时,通常会按 SCN 区间持续解析 redo 日志。对短事务来说,这种方式一般比较稳定。因为事务开始、数据变更和提交大多落在相近窗口内,同步链路比较容易还原完整结果。
长事务不一样。
它可能在较早的 SCN 开始,中间经历多次 DML,跨过多轮解析窗口,最后才提交或回滚。如果同步任务每轮都只从上次结束的位置继续向前读,当前窗口里看到的可能只是事务后半段,前面的定位信息、SQL 片段或前置变更已经不在当前解析范围里。
这里还有一个容易被忽略的点:START_LOGMNR 的起点会直接影响 V$LOGMNR_CONTENTS 产出的逻辑事件。这个起点并不等同于一次 SCN >= startScn 的结果过滤。起点如果刚好落在长事务、BLOB 更新链路或长 SQL 片段的中间位置,LogMiner 可能因为缺少前置上下文,��无法还原原本可识别的 DML 事件。
所以现场看到的,往往会是更隐蔽的问题:
- BLOB 更新被拆成 locator 和写入片段后,如果缺少前置上下文,后续
LOB_WRITE可能无法被正确识别或归属。 - 长 SQL 被拆成多段记录后,如果缺少前置片段,LogMiner 可能无法把它还原为可解析的 DML。
- rollback 依赖的前置 DML 不在当前解析窗口内时,回滚记录可能无法被正确识别和作用。
- 大事务跨窗口后,目标端可能残留源端最终并未生效的数据。
因此,长事务问题的核心在于事务上下文不完整,单纯关注某一条日志是否读取成功,通常很难定位根因。
Oracle 数据同步不一致的典型现象
如果你的 Oracle 同步链路存在长事务上下文处理不足,通常会在以下几类现象中暴露出来。
- 目标端多出数据:源端事务最终回滚,但目标端已经写入了变更。
- 目标端字段值不完整:部分大字段、长文本或复杂更新未能完整还原。
- BLOB 文件损坏或内容不一致:附件、图片、票据影像等字段在目标端无法打开,或内容与源端不同。
- 偶发性更强:同一张表大部分时间正常,只有在批处理、补数据、大对象写入或业务高峰时出现问题。
- 任务表面正常:同步任务没有明显失败,但数据校验能发现差异。
这些现象的共同点是:目标端没有拿到源端事务提交后的最终结果,而是落入了某个中间状态、残缺状态,或者本应被回滚的状态。
BLOB 同步场景:locator 和 LOB_WRITE 上下文丢失
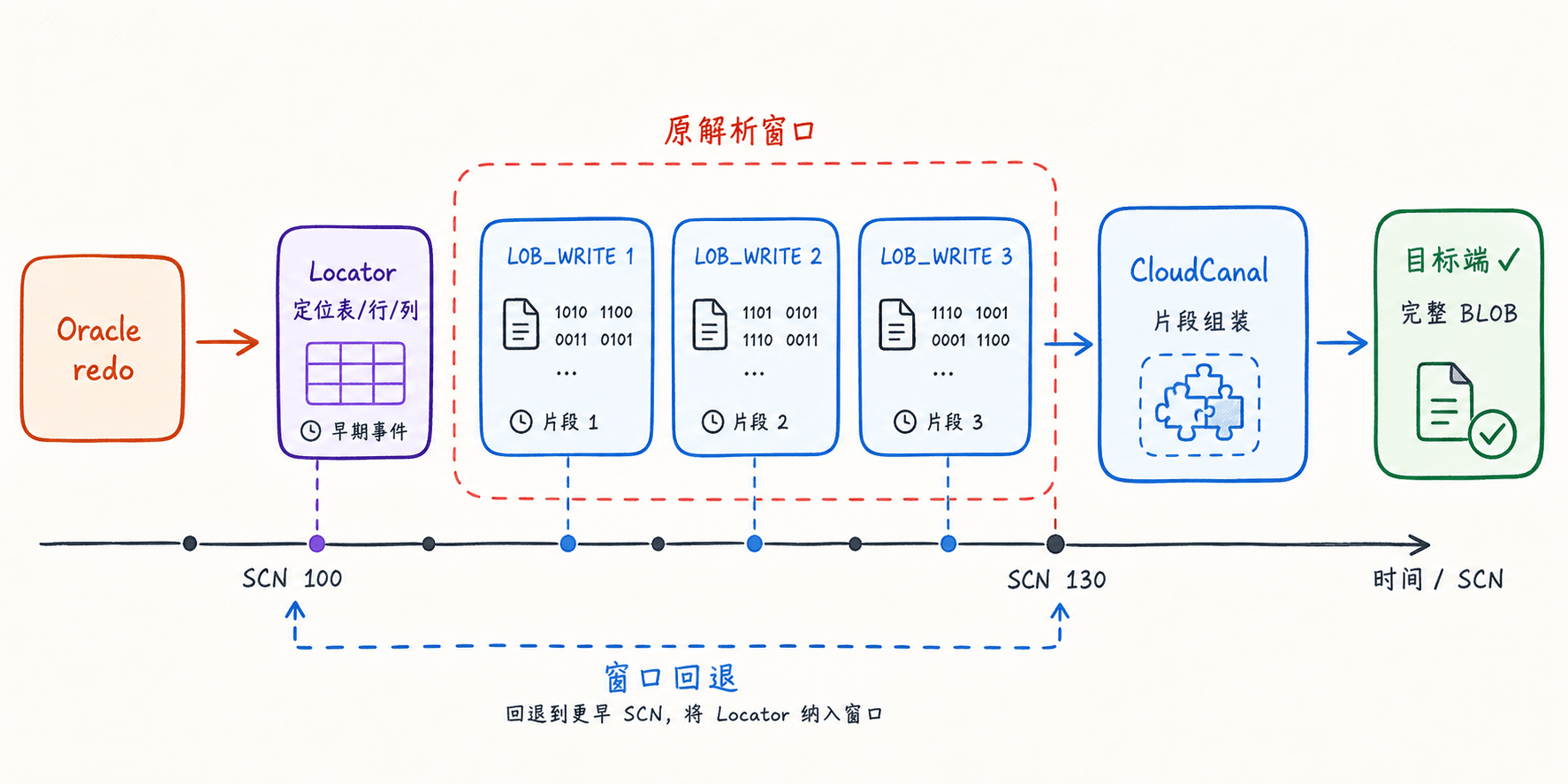
如果库里有附件、图片、票据、影像这类字段,BLOB 往往是最先暴露问题的地方。
原因不复杂。Oracle 对 BLOB 的 redo 表达方式,和普通字段更新不一样。一次 BLOB 更新,通常不会表现为一条完整的 UPDATE ... SET blob_col = ...。它往往会先出现定位目标行和目标列的 locator 事件,然后再出现多次 LOB_WRITE 写入事件。
如果 LogMiner 的解析窗口刚好切在这条链路中间,前面的 locator 不在当前上下文里,后面的 LOB_WRITE 就可能无法被正确识别,或者无法被正确归属到目标表、目标列和目标行。
最后看到的现象,通常不是“任务失败”,而是目标端文件不完整,或者大字段内容直接错误。
对同步链路来说,BLOB 的难点远不止“大对象传输”。它强依赖事务上下文、行列定位信息、片段顺序和提交回滚状态。只要其中一段上下文断掉,最终结果就可能偏离源端。
CSF 长 SQL 场景:SQL_REDO 分片还原失败
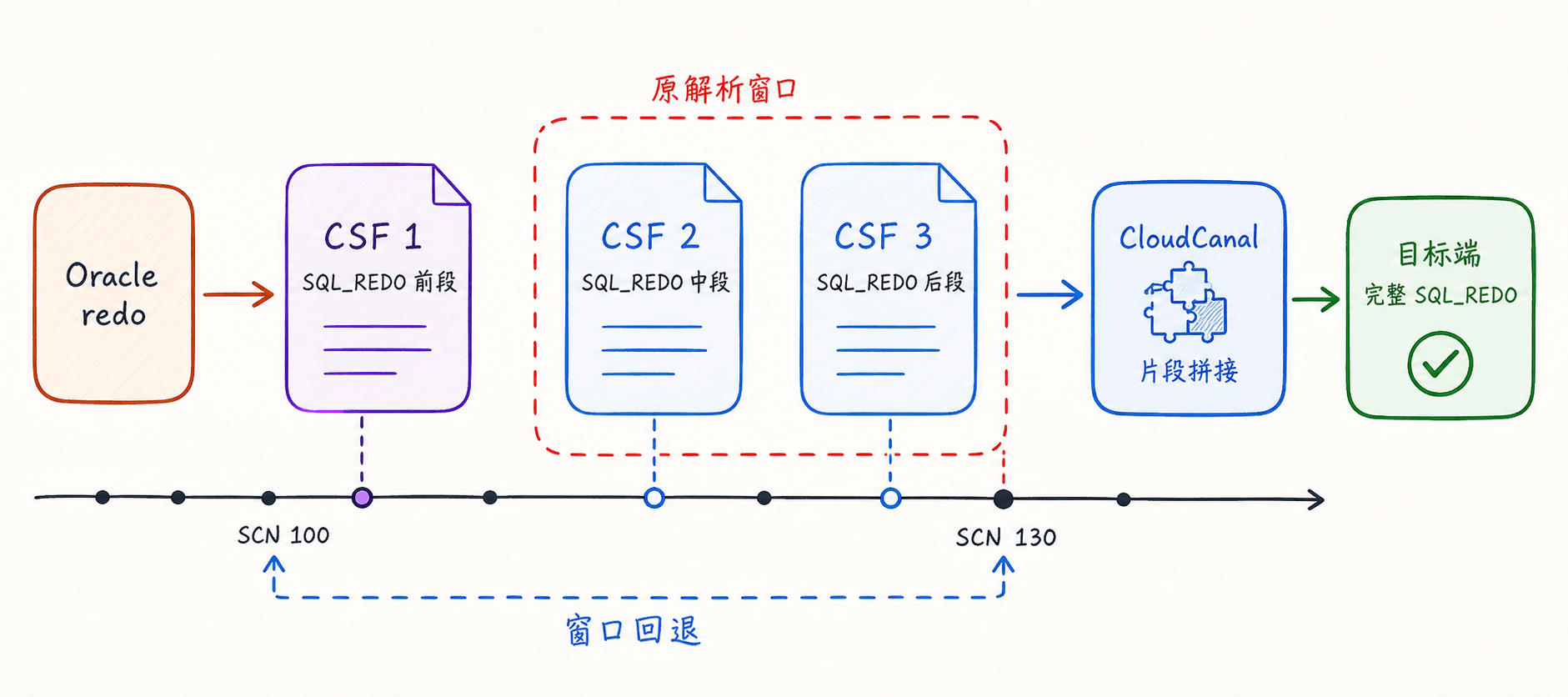
再看长 SQL。
当 SQL_REDO 内容过长时,LogMiner 可能会通过 CSF 等方式把一条完整 SQL 拆成多段记录。只有片段收全了,链路才能正确还原出完整 DML。
如果这条 SQL 又落在长事务里,而 START_LOGMNR 起点刚好切在中间片段附近,影响会进一步扩大。缺少前置上下文时,LogMiner 可能无法把这些 redo 还原成原本可识别的业务 DML,最终产出 Unsupported 这类无法用于字段解析的记录。
在字段很多、字段值很长、更新语句体积也大的表上,这类问题会更明显。例如大宽表、包含长文本字段的业务表、一次更新大量列的补偿任务,都更容易触发长 SQL 拆分和跨窗口解析问题。
对于同步工具而言,处理 CSF 长 SQL 不能只看当前行日志,还需要判断片段是否完整、是否属于同一条 SQL、是否属于同一事务,以及是否已经具备足够上下文进行结构化解析。
Rollback 场景:回滚记录无法单独理解
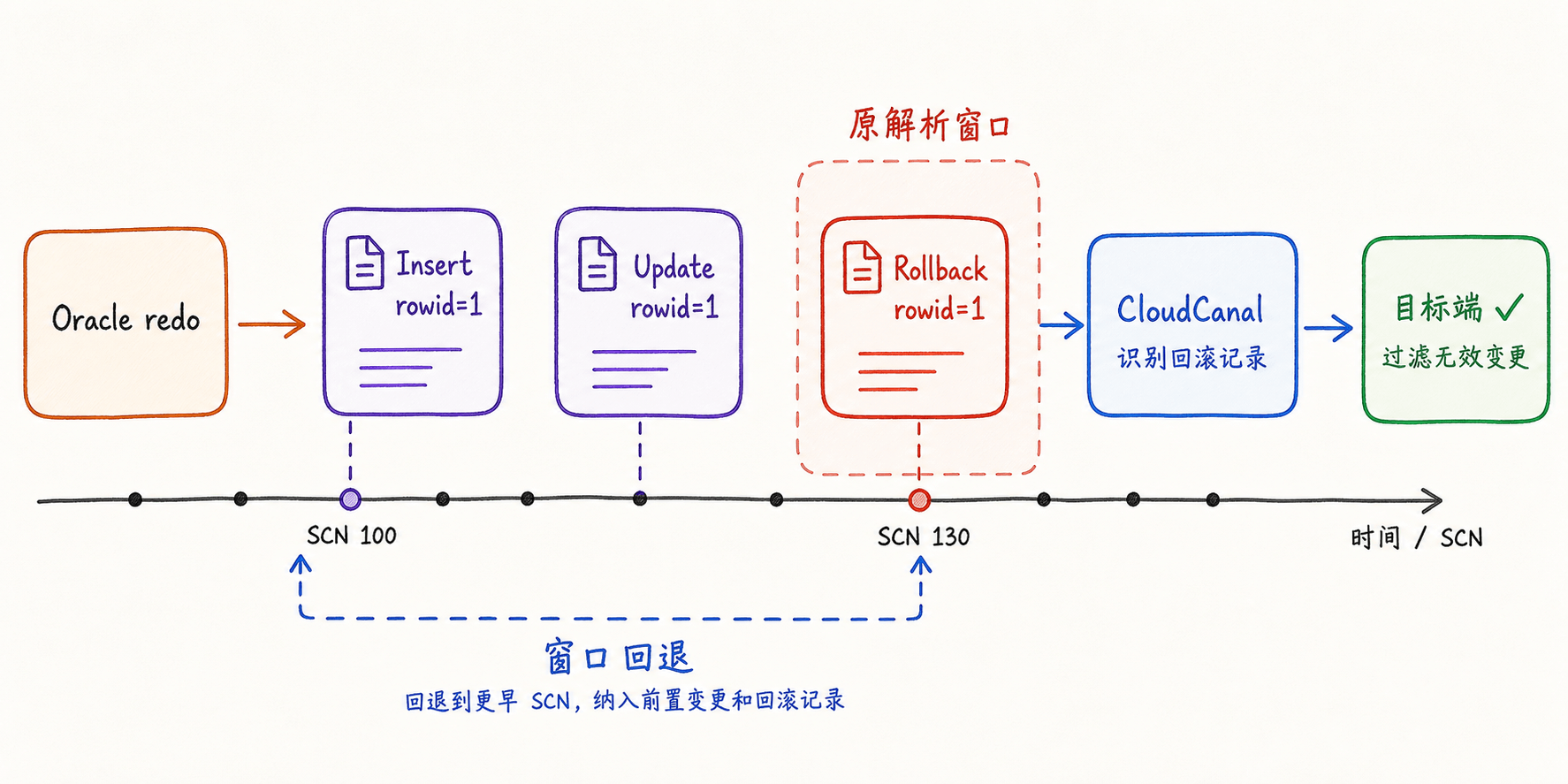
rollback 也是很典型的一类问题。
它麻烦的地方在于,rollback 记录很多时候不能脱离前置 DML 单独理解。如果当前窗口里看到了 rollback,但前面同事务、同 rowid 的 insert 或 update 已经不在解析范围内,那么这次撤销操作就可能无法被完整识别。
最后的结果就是:链路看到了变更,但没有正确处理它最终被回滚这件事。目标端留下的,可能是源端并未正式生效的数据。
所以很多同步链路除了回看窗口,还需要事务级暂存或延迟确认机制。否则即使拿到了 rollback 记录,也不一定能正确作用到之前已经暂存或待投递的变更上。
更稳妥的方式是:在事务提交前,不把未确认变更当成最终结果直接投递;在事务回滚时,能够按事务维度清理对应缓存、临时文件和待发送事件。
为什么简单回退 SCN 不一定够
遇到上下文丢失,很多人第一反应是把 SCN 往前回退一段。这确实能缓解一部分问题,但效果有明显边界。
原因在于,长事务没有固定长度。某些批处理事务可能持续数十分钟甚至数小时,BLOB 或长 SQL 的关键上下文也不一定刚好落在固定回退区间内。如果回退窗口太小,仍然可能切在事务中间;如果回退窗口太大,又会带来重复解析、性能下降和去重压力。
因此,稳定处理这类问题,不能只依赖“多读一点日志”。同步链路还需要在事务维度维护状态,知道哪些事务尚未结束,哪些上下文必须保留,哪些事件需要等 commit 或 rollback 后再决定最终动作。
这类问题本质上需要哪些能力
如果要处理上面这些问题,同步链路通常至少需要补齐几类能力。
事务级状态跟踪
同步链路不能只按日志窗口推进,还需要持续跟踪未完成事务。对于每个事务,链路要知道它已经出现过哪些 DML、是否包含 BLOB 或长 SQL、是否已经提交或回滚。
未完成事务上下文保留
只要事务还没结束,关键上下文就不能轻易丢弃。对于跨窗口事务,链路需要保留 locator、rowid、列信息、SQL 片段、临时大对象内容等必要信息。
BLOB、CSF 等特殊记录重组能力
BLOB locator、LOB_WRITE、CSF 长 SQL 片段等记录都需要被重新组织。这些事件必须放回事务、表、行、列和片段顺序中理解,单独处理很容易丢失语义。
Rollback 延迟处理能力
对于未提交事务,链路要避免过早把中间状态写入目标端。遇到 rollback 时,需要能按事务维度丢弃或清理相关变更,避免无效数据进入下游。
大事务暂存和恢复能力
长事务往往伴随大量变更。如果全部放在内存里,容易影响任务稳定性。因此同步链路需要具备可控的暂存能力,并能在任务异常重启后恢复未完成事务状态。
排查和选型时建议关注什么
如果你正在排查 Oracle 同步不一致,或者正在评估 Oracle CDC 同步方案,建议重点关注这些问题:
- 是否按事务维度处理增量数据,避免只依赖 SCN 窗口推进。
- 是否支持大事务、长事务的暂存和恢复。
- 是否能正确处理 BLOB、CLOB、长 SQL、CSF、rollback 等特殊场景。
- 是否在 commit 前保留事务语义,避免未提交数据提前进入目标端。
- 是否具备数据校验和订正能力,能在问题发生后快速定位并修复差异。
- 是否提供可观察指标,例如未提交事务数、LogMiner 解析速率、同步延迟、暂存大小等。
对于生产链路来说,Oracle CDC 的核心不仅在于“能不能读 redo”,还在于读到之��后,能不能在事务维度把这些记录重新组织成源端真正提交过的结果。
总结
在 Oracle 同步排查中,附件损坏、字段值异常、回滚未生效,或者目标端出现多余数据等问题,有时都可以追溯到事务上下文跨窗口丢失。
长事务会把原本紧凑的变更过程拆散到多个 LogMiner 解析窗口中。BLOB、CSF 长 SQL 和 rollback 又进一步放大了这种风险。同步链路如果只按窗口读取日志,而没有事务级上下文管理,就很容易得到残缺的中间状态。
因此,Oracle 数据同步的准确性,关键不仅在于读到日志,还要能理解日志背后的事务语义。只有把事务上下文、特殊记录重组、提交回滚处理和大事务暂存一起做好,目标端结果才更可能接近 Oracle 源端的最终提交状态。