用一条表达式,稳定同步上万张表

在现代业务环境中,“表太多” 已成为数据库同步领域越来越普遍的现象。一个成熟的业务背后,数据库中经常有几千张��甚至上万张表。在这种规模下,一旦某张表未被同步,下游数仓和分析链路就可能出现断层。
在这样的背景下,如何实现海量表稳定、可扩展的数据迁移同步,成为一个亟待解决的问题。本文将围绕这一挑战展开分析,并分享一种新的解决思路 —— 基于表达式的表名匹配机制。
上万张表同步,难在哪里?
多表同步的挑战,并不只是数量多,而是表规模扩大带来的复杂性,尤其当表的数量达到千级或万级后,传统方式的同步有效性会大打折扣。
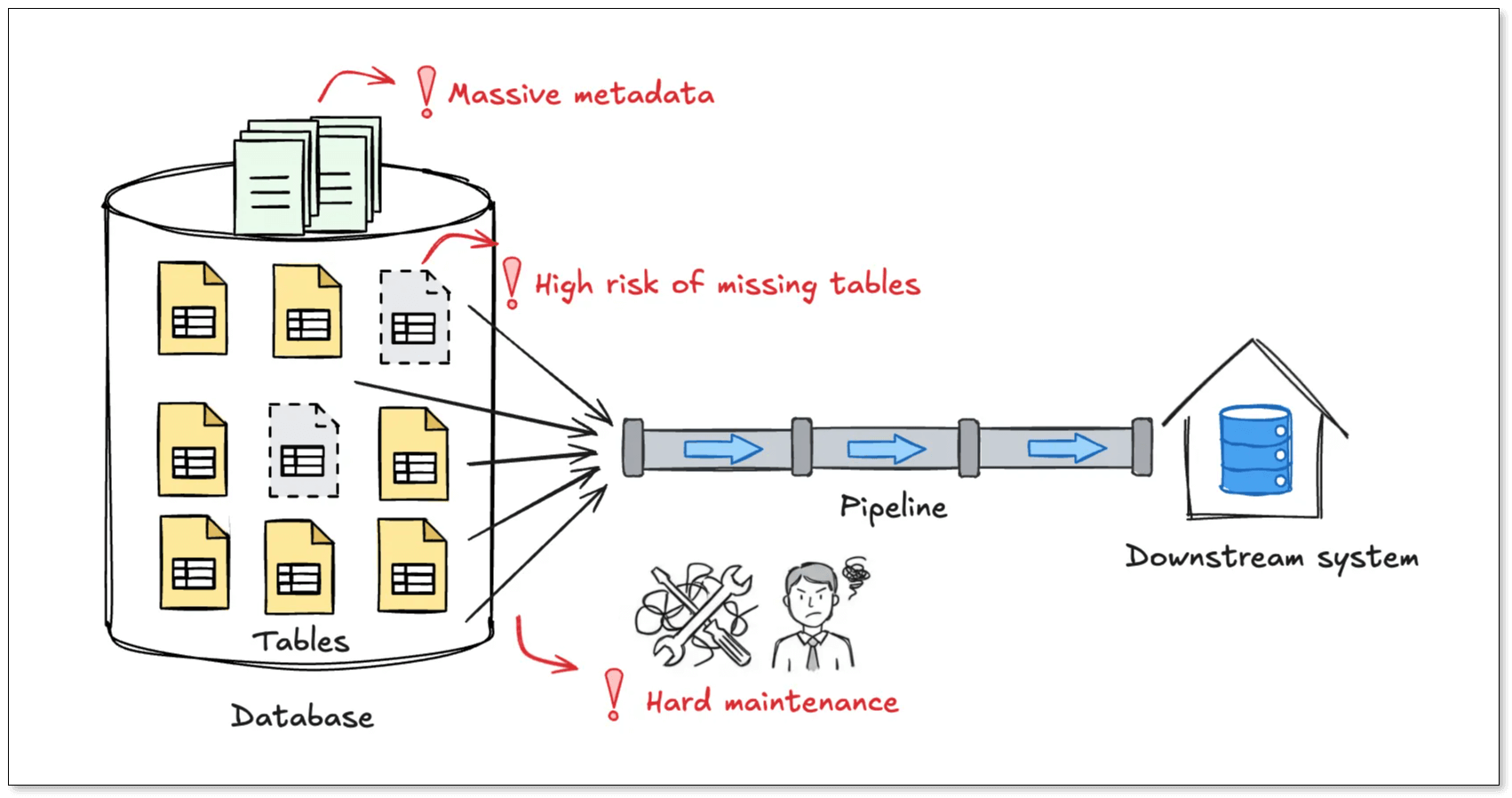
- 漏表风险极高:传统白名单模式依赖手动选择表。一旦漏选,下游系统将缺失对应数据,而且这种问题往往不会立即暴露,等发现时排查问题会非常困难。
- 元数据急速膨胀:常规同步工具会在任务配置中记录所有表的结构信息,如:列名、类型、主键信息、映射规则等。在表数量较少时,这种方式没有明显问题,但如果有成千上万张表,配置文件体积可能膨胀到 MB 级,大大降低了同步性能。
- 新增表频繁,维护困难:对日志、事件类业务而言,每天新增几十张表并不罕见。在白名单模式下,每次新增都要修改同步任务或新建任务,并且依然存在漏选表的风险。
常见解决方案
对于大量表的迁移同步,通常有以下几类解决思路:
- 人工维护白名单:这是最常见的做法。在创建同步任务时,通过界面或配置文件明确指定需要同步的表。这种方式能清晰划定同步的范围,并精细化配置数据转换、设置虚拟列等处理流程。但在大规模场景下,人工维护的难度和错选漏选的风险将大幅提升。
- 全库同步:为了彻底避免漏表风险,一些团队会选择直接开启全库同步,这能绕过白名单维护的问题。但在实际使用中会发现这种方案不够灵活,无法过滤不需要的表。另外,同步工具仍然需要获取并维护所有表的结构信息,元数据规模仍会随着表数量的增长而增长。

从本质上看,以上两种方式都是基于枚举的思路,即同步任务中必须明确指定具体的表,表越多,元数据越大,维护成本越高。
而数据迁移同步工具 CloudCanal 提出了一个不同的解法:不再枚举表,而是用规则定义表的集合。
表达式匹配表名机制
CloudCanal 5.3.0.0 版本引入了基于正则表达式的表名匹配机制。只要表名符合表达式,都将自动纳入同步任务中,这种方式将传统的 手动选择表 转化为 定义表范围,一个表达式,即可覆盖成千上万张表,例如:
- AAAA_ 开头加数字的表:
^AAAA_\d+$ - 同步整个库:
.*
这种方式在海量表的同步场景下具备明显优势,主要体现在以下几个方面。
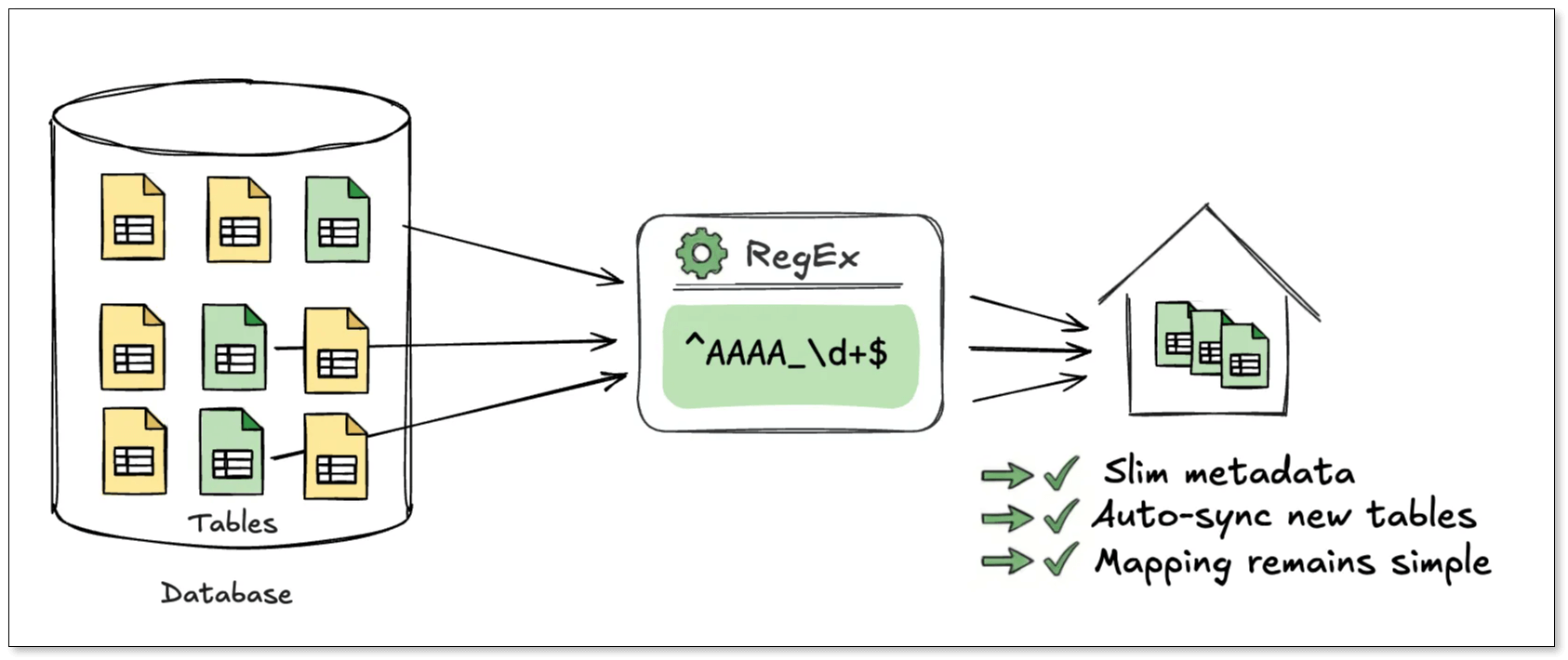
-
精简元数据
传统白名单任务会在配置里写入所有表的结构,并生成完整 mapping。而表达式任务则完全不同,不会读取所有表结构,仅记录表达式本身,因此不会产生大量的元数据,即使同步几万张表,配置依然只占几 KB 内存。 -
自动增减表
在同步链路支持CREATE / DROP TABLEDDL 的情况下,后续源端数据库中新增或删除表,只要表名满足表达式,这些表将自动加入或移出同步范围,无需手动维护。这既减少了漏选或错选表的风险,也大大简化了运维工作,对于每日分表、日志/事件系统、分库分表等场景都非常友好。 -
映射保持简洁
过去每一张表都会生成对应的映射规则,表越多,配置文件越大。而在表达式任务中,一条表达式对应一条映射规则,即使是一万张表,也只需要记录一条映射规则,非常适合数据汇聚、数据入湖等场景。
使用指南
下面通过一个简要的操作流程,展示如何用一条表达式,迁移同步一万张表。
前置准备
- 准备 RDS MySQL 实例。
- 登录 CloudCanal 云服务,并切换到 SaaS 模式。
添加数据源
- 点击 数据源管理 > 新增数据源。
- 配置数据源信息:
- 部署类型:自建
- 数据库类型:MySQL
- 网络地址:填写连接数据库的 IP 和 Host
- 认证方式:选择连接数据库的认证方式,并输入相应信息
- 点击 新增数据源。
创建任务
- 点击 同步任务 > 创建任务,进入创建任务流程。
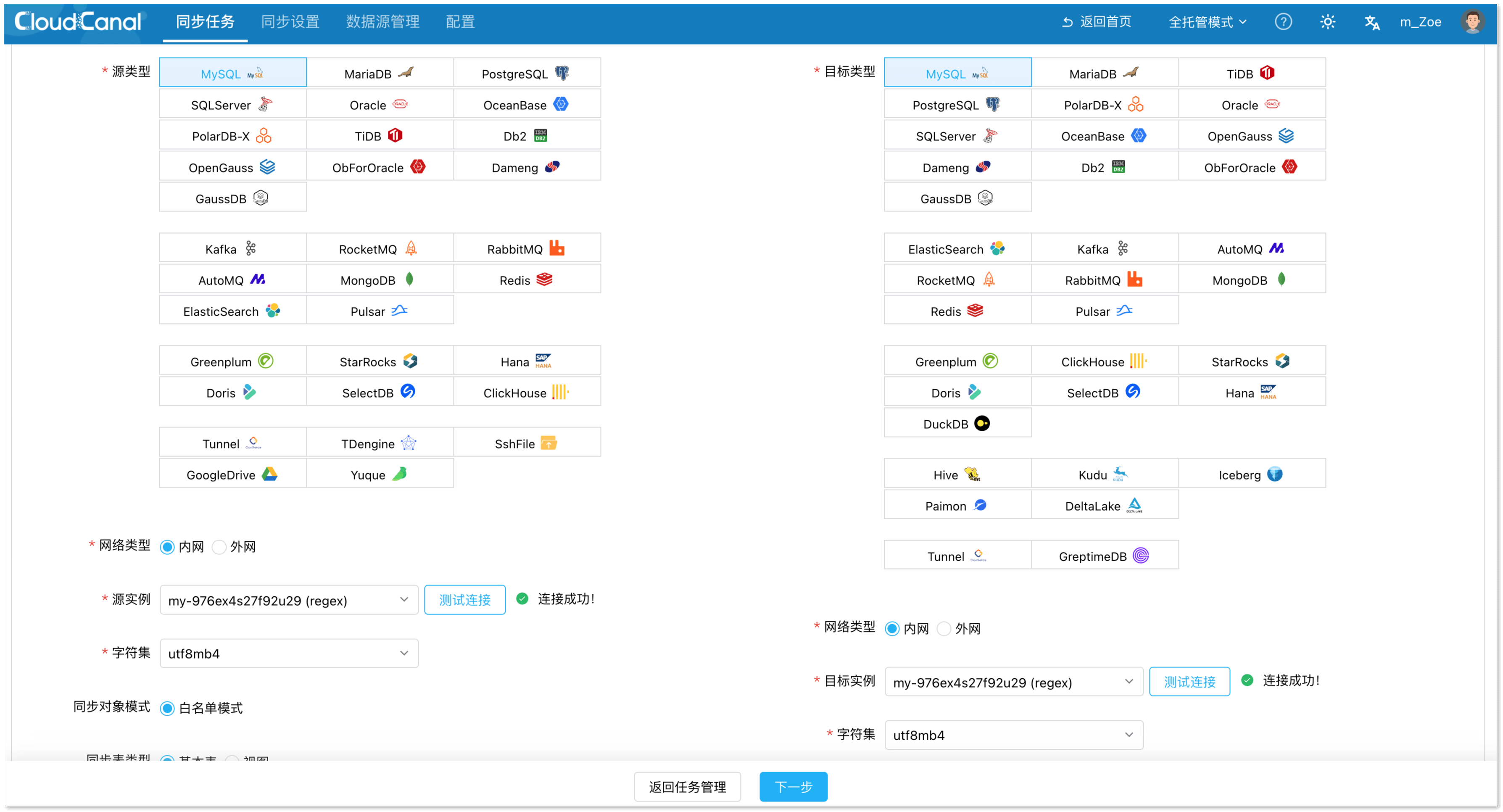
- 设置源库和目标库相关信息,选择源端和目标端实例,并分别点击 测试连接。
- 选择数据库或 Schema 等信息。
- 点击 下一步。
配置任务
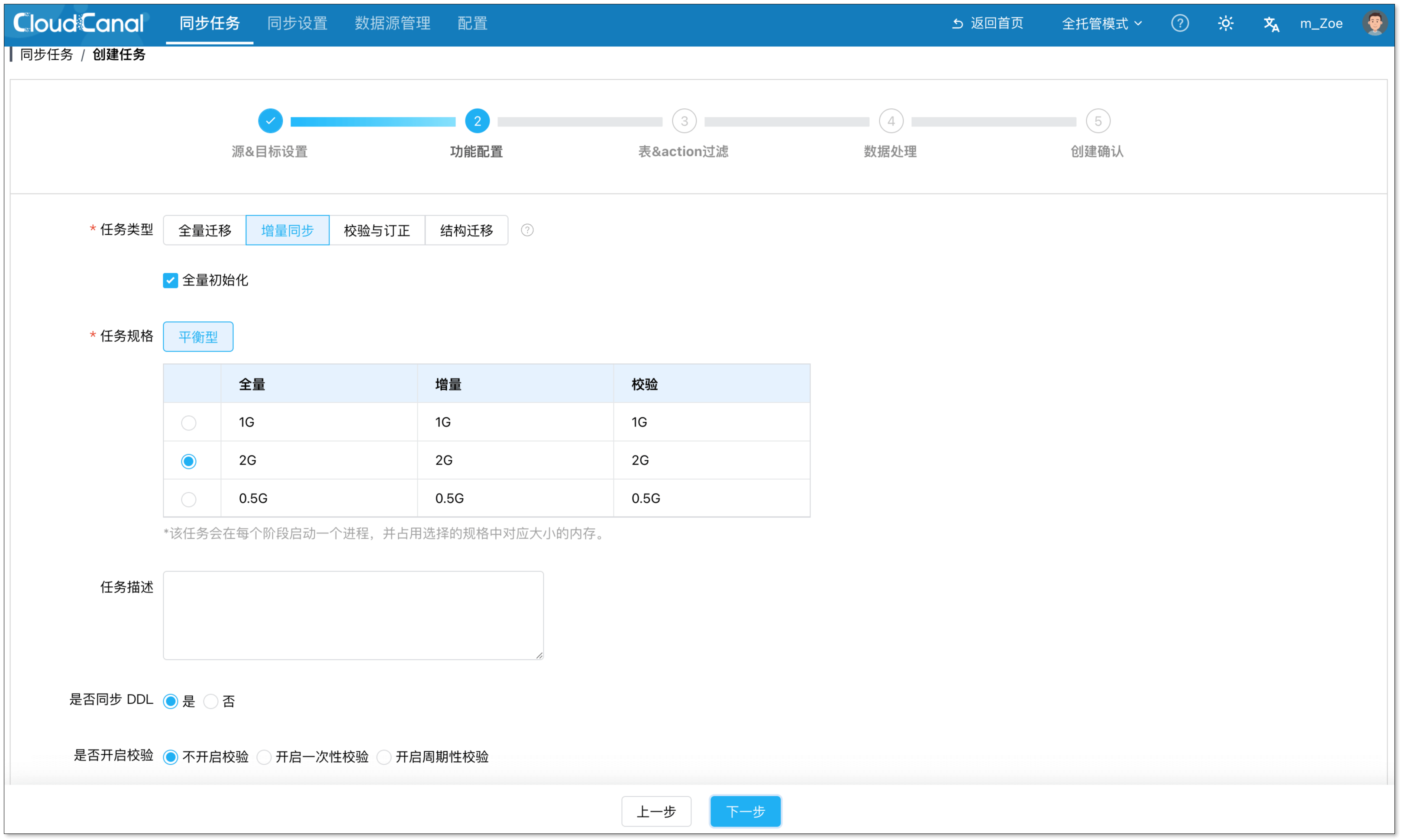
- 在功能配置页面,选择任务类型。默认选择 增量同步 并勾选 全量初始化。
- 选择任务规格。默认规格适配大部分场景。
- 点击 下一步。
选择数据表
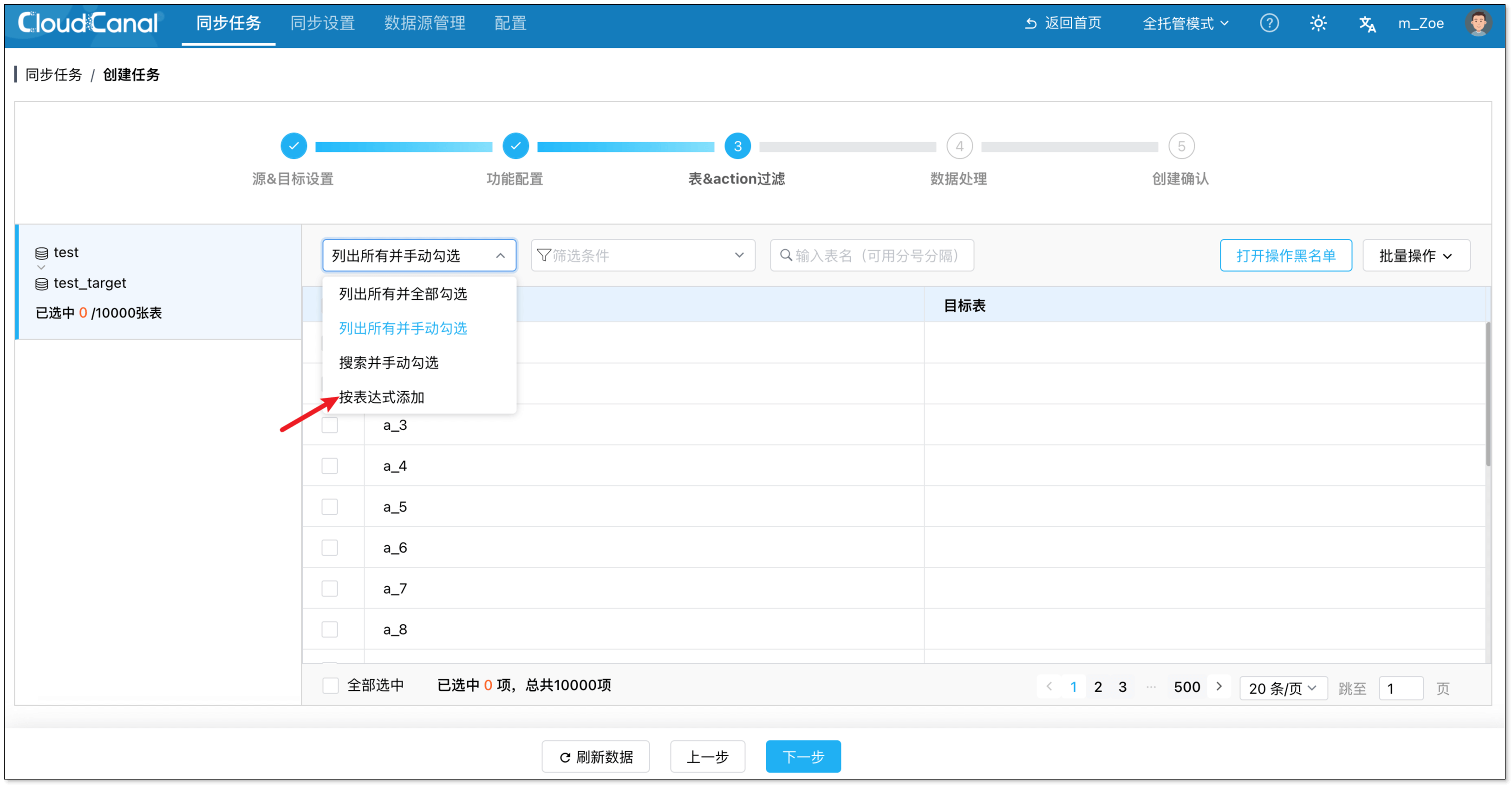
- 在表 & action 过滤页面,在左侧选择一个 schema。
- 在表格左上方下拉框选择 按表达式添加,设置正则表达式表名。如需增加表达式,可在左下方点击 新增表达式。默认为
.*正则表达式,表示迁移同步当前 schema 下所有的表。
目标表表名默认逐个映射为源端表表名。同时,支持手动输入目标表指定名称,在这一情况下,源端表将全部汇聚到这一目标表。
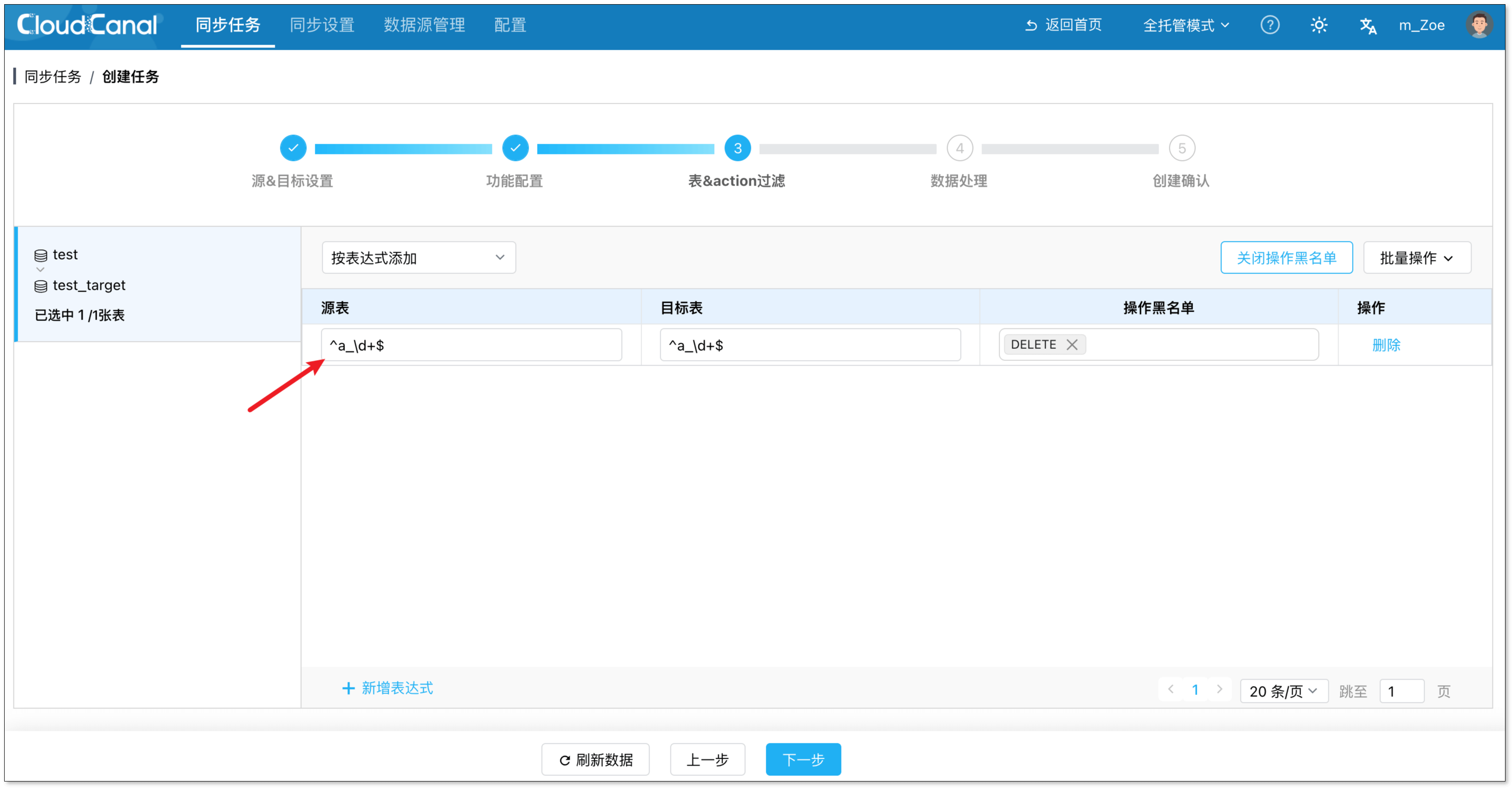
- 在表格右上方点击 打开操作黑名单,可过滤各类 DML/DDL 操作。
- 在表格右上方点击 批量操作,可 批量设置操作黑名单、修改目标表名、指定统一的映射规则。
- 点击 下一步。
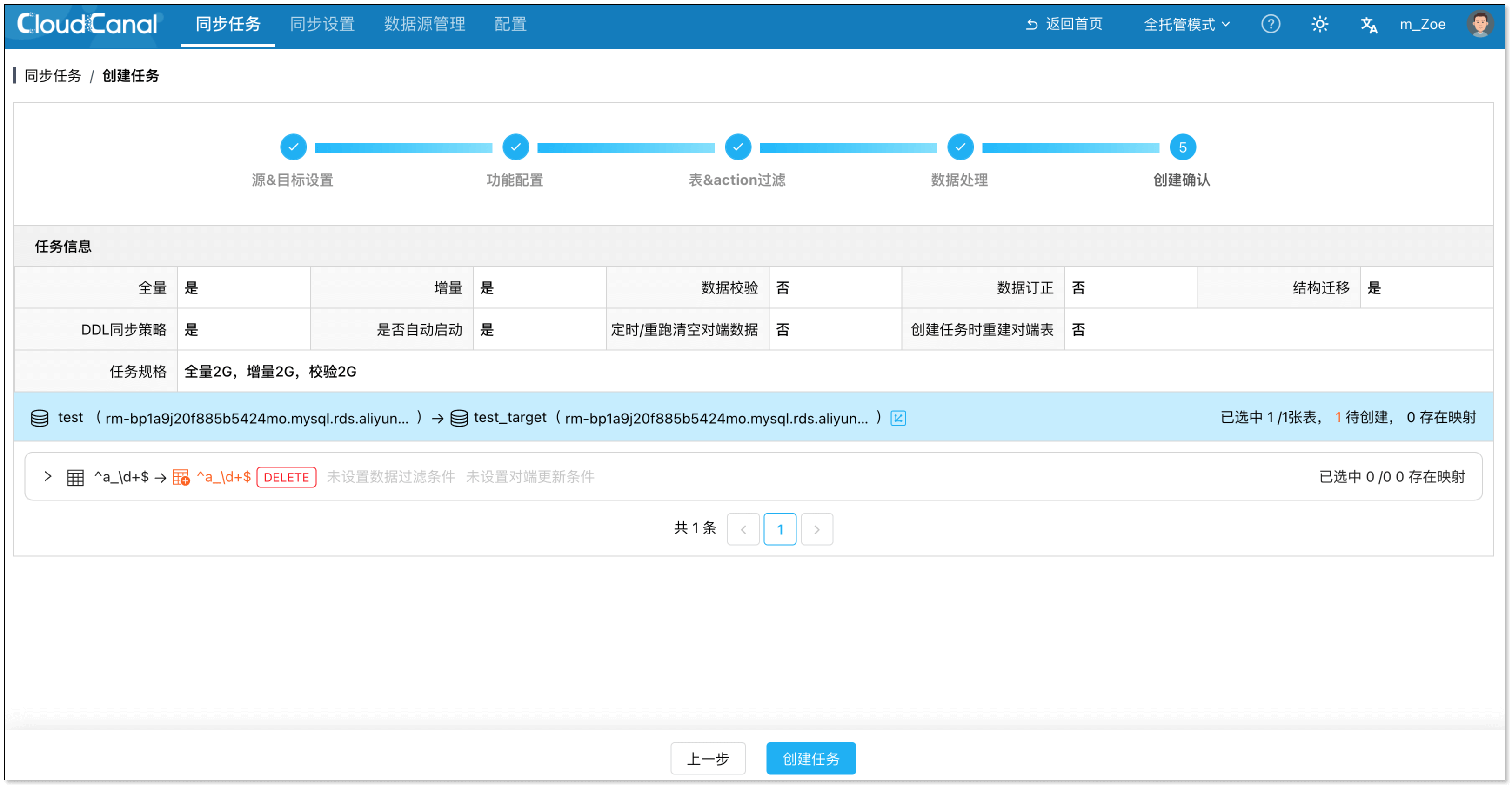
创建确认
- 在创建确认页面,确认任务信息。
- 确认无误后,点击 创建任务。
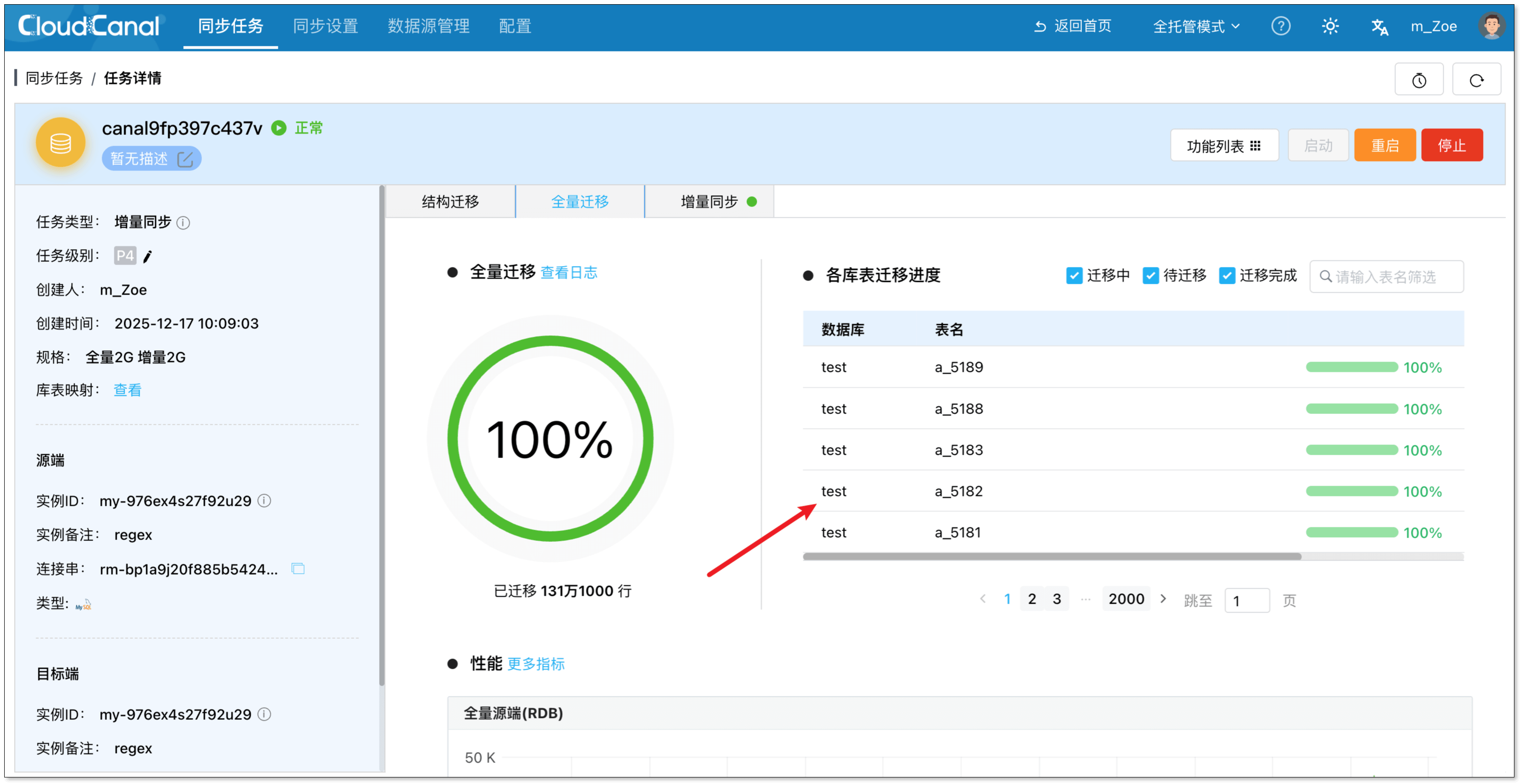
任务启动后,CloudCanal 会自动进行结构迁移、全量迁移、增量同步的任务流转。

在任务详情页,可以查看迁移同步的表。
结语
基于正则表达式的表名匹配机制,从根本上改变了海量表同步的配置方式。你不再需要管理每张表,而是通过规则来描述同步范围,从而有效解决了表数量大、变化频繁、元数据膨胀等一系列问题。对于正在面对上万张表同步挑战的团队来��说,这是一种更加稳定、轻量、也更符合实际需求的解决方案。