HANA 到 MySQL 数据同步

简述
SAP HANA 是一款列式存储的内存数据库系统,相比传统的硬盘存储数据库,数据处理速度更快,支持联机分析处理(OLAP)和联机事务处理(OLTP),常常用于实时分析处理、应用程序开发等场景。
MySQL 是在全球广泛使用的开源关系型数据库,历史悠久,运行稳定可靠,简便易用,灵活可扩展,因而受到许多组织的青睐。常用于 Web 应用的后端数据库、企业资源规划(ERP)系统的数据库、开发和测试数据库等。
本篇文章主要介绍如何使用 CloudCanal 构建一条 HANA 到 MySQL 的数据同步链路。
技术点
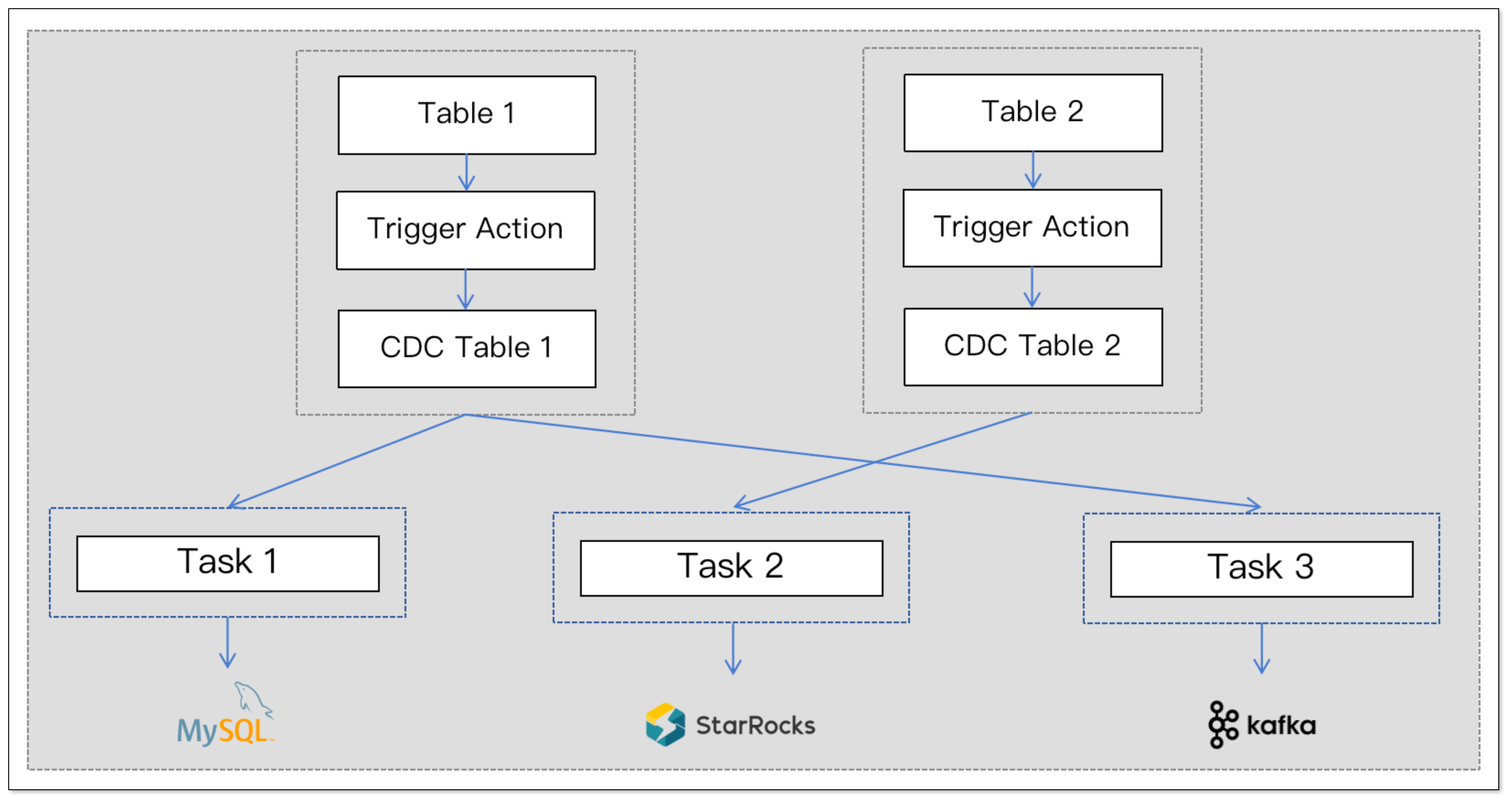
数据同步整体流程
CloudCanal 实现 HANA 源端增量数据同步,主要使用其触发器捕获变更事件。整体流程如下:
- 安装触发器,通过触发器捕获增量变更数据
- 记录位点,记录增量数据同步的起点
- 执行全量数据迁移
- 执行增量数据同步
表级别 CDC 表
CloudCanal 实现了表级别的 CDC 表设计,每张源表都对应一张 CDC 表,CDC 表的结构仅在原表结构的基础上增加了几个位点字段,用于增量同步。
相比于所有数据写入单一 CDC 表,表级别的 CDC 表更加独立,方便多次订阅表。此外,触发器只需要执行 INSERT 语句,因此对于字段较多的表也能够快速执行。扫描消费 CDC 数据时,不需要做额外的处理,消费更简单。
原表:
CREATE COLUMN TABLE "SYSTEM"."TABLE_TWO_PK" (
"ORDERID" INTEGER NOT NULL ,
"PRODUCTID" INTEGER NOT NULL ,
"QUANTITY" INTEGER,
CONSTRAINT "FANQIE_pkey_for_TA_171171268" PRIMARY KEY ("ORDERID", "PRODUCTID")
)
CDC 表:
CREATE COLUMN TABLE "SYSTEM"."SYSTEMDB_FANQIE_TABLE_TWO_PK_CDC_TABLE" (
"ORDERID" INTEGER,
"PRODUCTID" INTEGER,
"QUANTITY" INTEGER,
"__$DATA_ID" BIGINT NOT NULL ,
"__$TRIGGER_ID" INTEGER NOT NULL ,
"__$TRANSACTION_ID" BIGINT NOT NULL ,
"__$CREATE_TIME" TIMESTAMP,
"__$OPERATION" INTEGER NOT NULL
);
-- other index
触发器 (INSERT):
CREATE TRIGGER "FANQIE"."CLOUD_CANAL_ON_I_TABLE_TWO_PK_TRIGGER_104" AFTER INSERT ON "SYSTEM"."TABLE_TWO_PK" REFERENCING NEW ROW NEW FOR EACH ROW
BEGIN
DECLARE EXIT HANDLER FOR SQLEXCEPTION BEGIN END;
IF 1=1 THEN
INSERT INTO "SYSTEM"."SYSTEMDB_FANQIE_TABLE_TWO_PK_CDC_TABLE" (__$DATA_ID, __$TRIGGER_ID, __$TRANSACTION_ID, __$CREATE_TIME, __$OPERATION, "ORDERID","PRODUCTID","QUANTITY")
VALUES(
"SYSTEM"."CC_TRIGGER_SEQ".NEXTVAL,
433,
CURRENT_UPDATE_TRANSACTION(),
CURRENT_UTCTIMESTAMP,
2,
:NEW."ORDERID" ,
:NEW."PRODUCTID" ,
:NEW."QUANTITY"
);
END IF;
END;
表级别任务位点
在表级别 CDC 表模式下,同步增量数据时,每个表都有自己的位点,原有的单一位点无法满足这种同步需求。
因此,CloudCanal 引入了表级别的增量同步位点,确保每个表能够消费各自对应的增量同步位点。位点的具体体现为:
[
{
"db": "SYSTEMDB",
"schema": "FANQIE",
"table": "TABLE_TWO_PK",
"dataId": 352,
"txId": 442441,
"timestamp": 1715828416114
},
{
"db": "SYSTEMDB",
"schema": "FANQIE",
"table": "TABLE_TWO_PK_2",
"dataId": 97,
"txId": 11212,
"timestamp": 1715828311123
},
...
]
这样的设计有以下好处:
-
位点精细控制:每个表都有自己的增量同步位点,在增量任务中可以重新消费特定表中的增量数据,而无需消费所有表的数据,实现更加精细的控制,减少不必要的数据传输和处理,提高同步效率。
-
数据并行处理:由于每个表有自己的位点,可以实现表级别的并行处理。不同表的增量数据可以同时处理,避免了单一位点导致的串行处理瓶颈,从而加快了同步速度。
操作示例
步骤 1: 安装 CloudCanal
请参考 全新安装(Docker Linux/MacOS),下载安装 CloudCanal 私有部署版本。
步骤 2: 添加数据源
登录 CloudCanal 控制台,点击 数据源管理 > 新增数据源 。
步骤 3: 创建任务
-
点击 同步任务 > 创建任务。
-
配置源和目标数据源。
- 选择源和目标实例,并分别点击 测试连接。
- 在目标实例下方 高级配置 中选择源端 CDC 表模式:单 CDC 表 / 表级 CDC 表。
-
选择 数据同步 并勾选 全量初始化。
-
选择需要同步的表。
-
选择表对应的列。
信息如果需要选择同步的列,可先行在对端创建好表结构。
-
点击 确认创建。
信息任务创建过程将会进行一系列操作,点击 同步设置 > 异步任务,找到任务的创建记录并点击 详情 即可查看。
HANA 源端的任务创建会有以下几个步骤:
- 结构迁移
- 初始化 HANA CDC 表以及对应触发器
- 分配任务执行机器
- 创建任务状态机
- 完成任务创建
-
等待任务自动流转。
信息当任务创建完成,CloudCanal 会自动进行任务流转,其中的步骤包括:
- 结构迁移: HANA 源端的表定义将会迁移到对端,如果同名表在对端已经存在,则会忽略。
- 全量数据迁移: 已存在的存量数据将会完整迁移到对端。
- 增量数据同步: 增量数据将会持续地同步到对端数据库,并且保持实时(秒级别延迟)。
总结
本文简单介绍了如何使用 CloudCanal 进行 HANA 到 MySQL 数据迁移同步,打通数据流动的渠道,实现端到端的精准数据传输。