MySQL 迁移到 Snowflake 怎么做?4 种常见方案对比(不停机/准实时)

你可能已经感觉到:把分析业务跑在 MySQL 上,越来越吃力了。
- BI 报表一多就�超时,临时分析把线上库打得 CPU 飙升
- OLTP(业务读写)和 OLAP(分析查询)互相抢资源
- 业务希望“准实时看数”,但又不敢让分析师直连生产库
这时,Snowflake 往往是一个很自然的目的地。但 MySQL → Snowflake 迁移很少是“把数据搬过去”这么简单:真正难的是在不影响线上业务的前提下,完成全量迁移、持续追增量、验证一致性,并安全切换。
这篇文章我们对比了 4 种在生产中常用的 MySQL 迁移/同步到 Snowflake 的方法:从一次性导入,到可实现 不停机(或近似不停机) 的 CDC 持续复制,并给出选型建议。
1. 手动导出导入(CSV / SQL dump)
2. 批量 ETL(定时增量)
3. Kafka 流式(MySQL → Kafka → Snowflake)
4. 基于 CDC 的准实时复制(MySQL binlog → CloudCanal CDC → Snowflake)
MySQL 是什么?

MySQL 是最常见的开源关系型数据库之一,广泛用于 Web、SaaS 等业务系统的事务场景(OLTP)。它支持索引、事务(InnoDB 的 ACID)、复制与高可用等能力;同时 MySQL 还提供 binlog(二进制日志) 记录行级变更——这也是很多 CDC(Change Data Capture,变更数据捕获) 方案的基础。
MySQL 当然也能做一些分析查询,但它并不擅长大范围扫描、复杂 join、大聚合、以及“多人并发分析”这种 OLAP 负载。
Snowflake 是什么?

Snowflake 是面向分析的云数仓/数据平台,更擅长 OLAP 工作负载。它的典型优势包括计算与存储分离(弹性扩缩、资源隔离)、更强的分析并发能力、对半结构化数据(如 JSON)的支持、以及安全的数据共享机制等。
很多团队会把 Snowflake 作为报表、建模和下游分析的“分析事实库”:业务数据在 MySQL 产生,但分析与建模更适合在 Snowflake 上完成。
为什么要从 MySQL 迁移到 Snowflake?
因为:MySQL 和 Snowflake 天生为不同的工作而设计。 MySQL 更适合服务应用流量(高频读写、低延迟、强一致); Snowflake 更适合规模化分析(大扫描、复杂 join、大聚合、多人并发)
当团队把分析查询长期跑在 MySQL(或脆弱的只读副本)上,通常会遇到三类问题:
- 性能瓶颈:报�表/临时查询把 CPU/IO 打满,影响线上事务延迟
- 扩展成本高:为了分析而扩容 MySQL,成本高且架构复杂
- 分析能力受限:现代 ELT/建模/多团队并发更适合在 Snowflake 上做
因此,MySQL → Snowflake 迁移/同步常见目标是:让 MySQL 专注 OLTP,把分析搬到 Snowflake;并选择一条符合停机窗口与数据新鲜度要求的迁移路径。
4 种把 MySQL 数据迁移/同步到 Snowflake 的方法
不存在永远最好的方法,选型通常取决于:
- 一次性迁移,还是长期 MySQL → Snowflake 增量同步
- 允许多少停机(分钟?小时?尽量不停机?)
- 数据新鲜度诉求(小时级/分钟级/秒级)
- 团队能承受的运维复杂度(自建 vs 托管)
下面是最常见的 4 种路径。
方法 1:手动导出导入(CSV / SQL dump)
流程示意:
将数据从 MySQL 迁移到 Snowflake 最朴素的方法就是从 MySQL 导出 CSV 或 SQL dump,再导入 Snowflake(例如通过文件落盘后 COPY INTO)。
基本步骤(适合一次性迁移)
- 从 MySQL 导出数据
- 常见方式:
mysqldump导出 SQL、或按表导出 CSV
- 常见方式:
- 把导出文件放到 Snowflake 可读取的位置
- 例如对象存储(S3/GCS/Azure Blob)或其他 Snowflake 可访问的 stage
- 在 Snowflake 创建表结构
- 手动建表,或根据导出结构生成 DDL
- 把数据加载进 Snowflake
- 常见方式:使用
COPY INTO批量加载(需要更持续的文件入仓可再评估 Snowpipe)
- 常见方式:使用
- 做迁移校验
- 行数对账、抽样比对、关键指标聚合校验、核心业务查询回归
参考文档:
- MySQL
mysqldump:https://dev.mysql.com/doc/refman/8.0/en/mysqldump.html - Snowflake
COPY INTO <table>:https://docs.snowflake.com/en/sql-reference/sql/copy-into-table
适用场景
- 数据量不大、一次性搬运
- 能接受停机/写入冻结窗口
- 对增量同步、删除语义、一致性要求不高
优点
- 最快上手,几乎零架构改动
- 成本低、依赖少
缺点(也是最常踩坑的点)
- 线上持续写入时很难保证一致性(导出过程中数据在变)
- 需要人工处理增量与回滚;数据量大时导出/导入耗时长
- 一旦要“迁移不停机”,手动方法基本就�不够用了
方法 2:批量 ETL(定时增量)
流程示意:
批量 ETL/ELT 的思路是:先做一次全量,然后按固定周期(小时/天/几分钟)跑增量,把变更同步到 Snowflake。
常见实现方式包括:
- 自写脚本 + cron
- Airflow 等调度器
- 各类 ETL/ELT 工具(商业或开源)
两种常见增量模式
模式 A:按时间戳增量(updated_at)
每次取 updated_at > last_watermark 的数据,再做 upsert。
updated_at严格可靠时效果不错- 但容易被“延迟更新、时间漂移、漏更新字段”等问题坑到
模式 B:按自增 ID 增量(id > last_max_id)
适用于“只追加”的事件表。
- 对追加型表简单有效
- 对更新/删除无能为力,除非额外引入补偿机制
优点
- 适合周期性报表(小时级/天级刷新)
- 对很多团队来说比流式更容易启�动
- 调度与资源使用可控
缺点
- 增量正确性没看起来那么简单(晚到更新、删除、去重、幂等)
- 组件更多:调度、状态存储、重试、告警、补数
- 要做到“准实时”往往意味着更高频任务与更大 MySQL 读取压力
方法 3:Kafka 流式(MySQL → Kafka → Snowflake)
流程示意:
如果你们已经把 Kafka 作为数据总线(或下游不止 Snowflake 一个消费者),Kafka 流式是很经典的架构:
- 从 MySQL 捕获变更(通常读 binlog)
- 写入 Kafka topic
- 用 Sink Connector 或自研消费程序落到 Snowflake
实现选择(高层级):
- Debezium + Kafka Connect(偏 DIY)
- 托管型 CDC 平台将变更写入 Kafka(降低运维)
- Snowflake 侧接入方式:
- Snowflake Kafka Connector(Kafka Connect sink)
- 自研 consumer:落文件/落 stage,再
COPY INTO
参考(Snowflake):Kafka Connector 文档:https://docs.snowflake.com/en/user-guide/kafka-connector-overview
优点
- 低延迟、事件驱动
- 多下游消费者时很合适
- 数据工程领域成熟方案
缺点
- 运维成本高(Kafka/Connect/Schema 演进/监控/告警)
- 端到端 exactly-once 很难,需要幂等与去重策略兜底
- 故障处理复杂(offset、回压、重放、堆积)
方法 4:基于 CDC 的准实时复制(CloudCanal)
流程示意:
如果你的目标是不停机(或接近不停机)的生产迁移,最常见也最稳的模式通常是:
- 先做一次全量导入到 Snowflake
- 通过 CDC 持续读取 MySQL binlog,把增量(增/改/删)准实时同步到 Snowflake
- 当延迟接近 0 且验证通过后,执行切换(优先切分析读)
CDC 的价值在于:它不需要反复扫表,而是读取变更日志来同步 insert/update/delete,更容易做到低延迟与更完整的删除语义。
CloudCanal 是一款面向生产的无需写代码的数据迁移与同步平台,可��以用“全量 + 增量 CDC”的一条任务完成 MySQL → Snowflake 的持续复制,降低自建 CDC 与运维 Kafka 的成本。
前置条件(简版)
MySQL 侧
- CloudCanal 能访问到 MySQL(网络联通)
- 开启 MySQL binlog(CDC 读取 binlog;通常建议
ROW格式以保证正确性) - 准备具备所需权限的账号
参考:MySQL 权限要求:https://www.clougence.com/docs/dataMigrationAndSync/datasource_func/MySQL/privs_for_mysql/
Snowflake 侧
- Snowflake 账号与目标 database/schema
- 具备建表、写入、加载数据等权限的 role
CloudCanal 侧
根据部署形态选择:
- SaaS 全托管:无需部署组件,注册/登录后即可创建任务开始同步
- BYOC(Bring Your Own Cloud):控制台在云上托管,数据面 Worker 部署在你们自有云/IDC,更便于满足网络与合规要求
- 私有化/本地部署:在自有环境部署控制台与 Worker,适合对内网隔离/合规要求更高的场景
配置步骤(示例:MySQL → Snowflake 全量 + 增量)
下面以控制台界面为例给出一个通用流程(不同版本 UI 细节可能略有差异)。
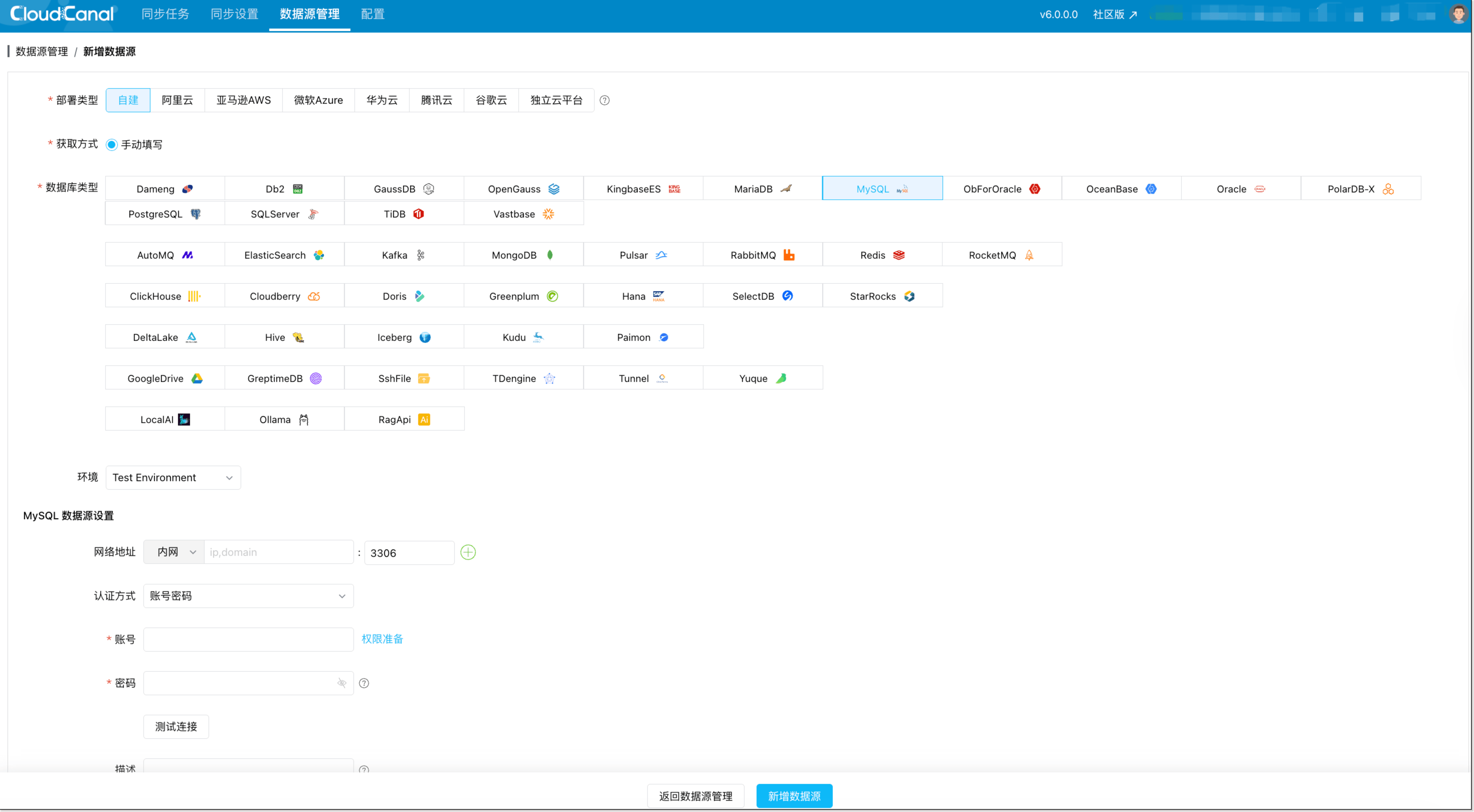
步骤 1:添加 MySQL 数据源
在 CloudCanal 控制台:
- 进入 数据源管理 → 新增数据源
- 选择 MySQL
- 填写 网络地址/账号/密码 等参数
- 点击 测试连接,通过后点击 新增数据源
步�骤 2:添加 Snowflake 数据源
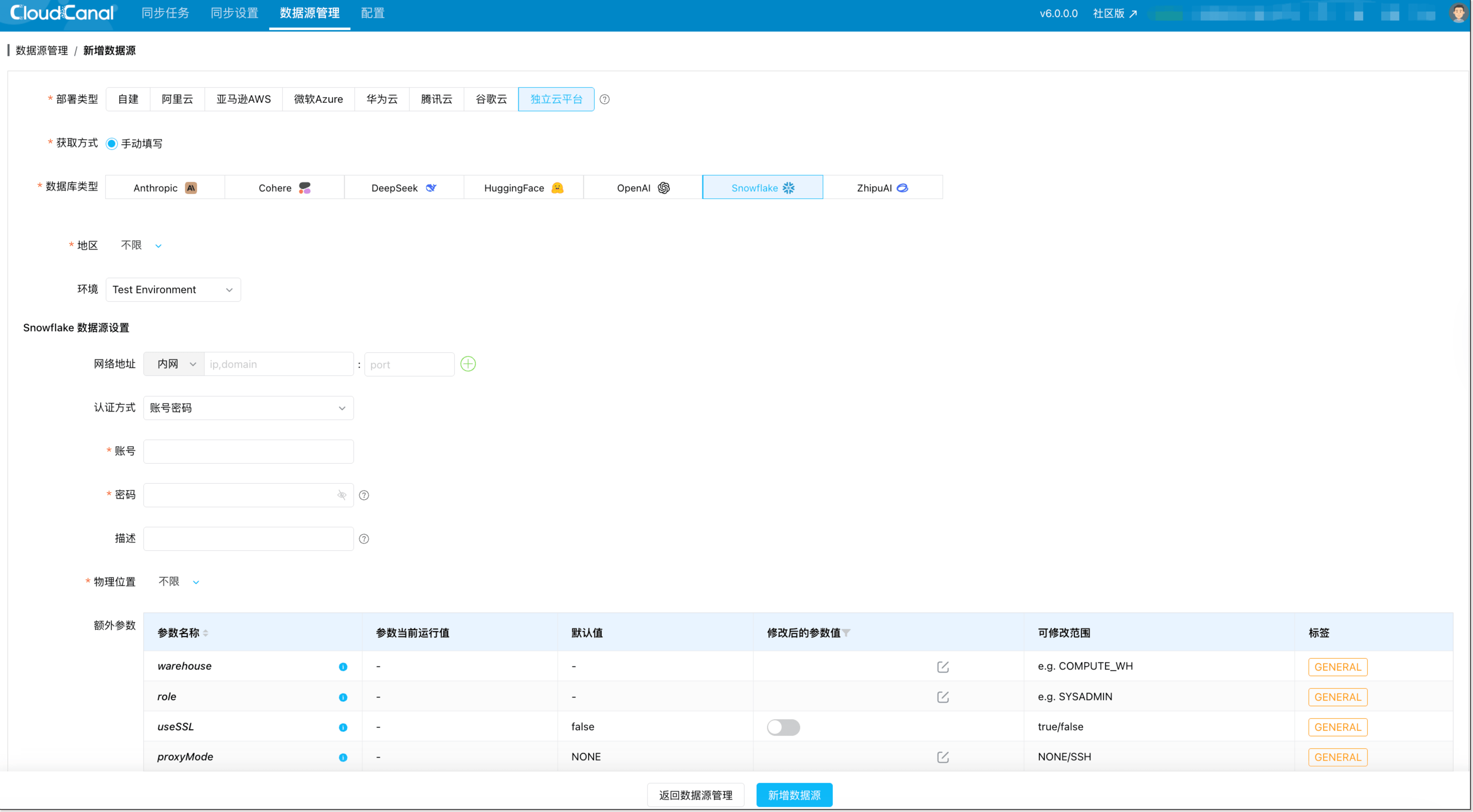
- 进入 数据源管理 → 新增数据源
- 选择 Snowflake
- 按你的认证方式填写 网络地址/账号/密码 等参数
- 点击 测试连接,通过后点击 新增数据源
步骤 3:创建任务(全量 + 增量 CDC)

- 进入 任务 → 创建任务
- 选择源端 MySQL,目标端 Snowflake
- 选择 增量同步 + 全量初始化
参考:创建全量+增量任务:https://www.clougence.com/docs/operation/job_manage/create_job/create_full_incre_task/
步骤 4:选择表与映射规则
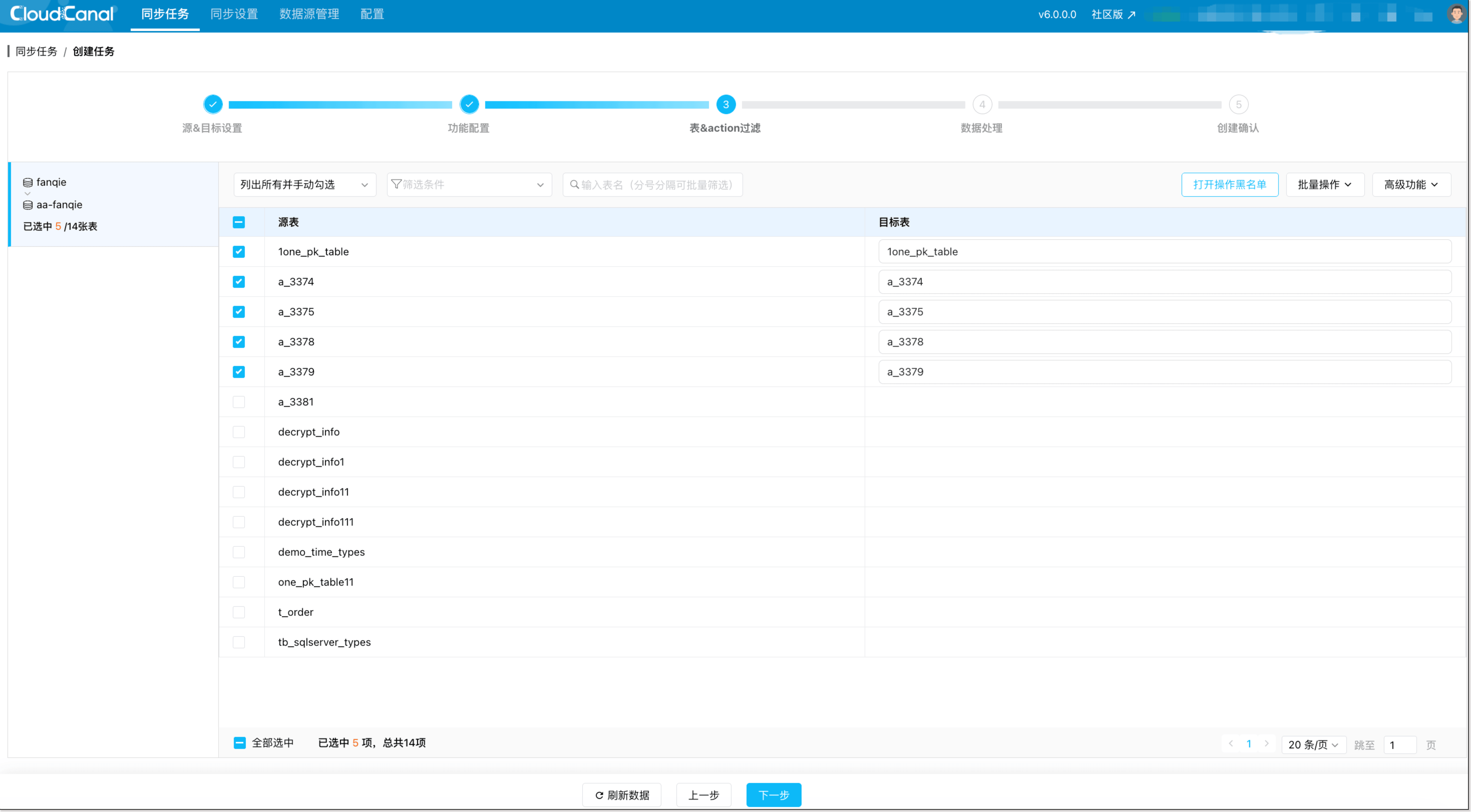
- 勾选需要同步的表
- 按需配置(如):
- 目标名称
- 目标映射规则
- 黑名单
步骤 5:选择列并启动

- 选择需要同步的列
- 按需配置(如):
- 目标映射规则
- 数据过滤条件
- 目标主键
- 自定义代码(如有)
- 确认无误之后创建并启动任务
对比:MySQL → Snowflake 方案怎么选?
下面是一个更偏“工程落地”的对比(仅供快速选型):
| 维度 | 方法 1:手动导出 | 方法 2:批量 ETL | 方法 3:Kafka 流式 | 方法 4:CDC 复制(CloudCanal) |
|---|---|---|---|---|
| 停机时间 | 通常需要停机/冻结写入 | 低到中(取决于批量窗口) | 低(取决于链路成熟度) | 最小化/支持不停机迁移模式 |
| 实时性 | 不支持 | 有限(分钟到小时) | 支持(准实时) | 支持(准实时) |
| 复杂度 | 低 | 中 | 高 | 低到中(可托管、低代码/零代码) |
| 适用场景 | 小数据量一次性搬运 | 周期性报表、低频同步 | 已有 Kafka 体系团队 | 生产迁移、长期准实时复制 |
| 一致性 | 线上写入时风险高 | 依赖增量设计质量 | 做好去重/幂等后较好 | 强(全量快照 + CDC 位点跟踪) |
如果你明确需要“不停机/准实时/删除也要同步”,一般优先考虑 CDC(方法 4)。如果只是小数据量一次性迁移,方法 1 也能满足。
常见问题
MySQL 迁移到 Snowflake 怎么做到不停机(零停机)?
常用做法是 全量快照 + CDC 持续追增量 + 低停机切换:先把历史数据导入 Snowflake,再持续同步 MySQL binlog 的变更;当延迟接近 0 且校验通过时,安排一个很短的窗口完成切换(通常先切分析读)。
CDC 同步 MySQL 会不会影��响性能?
CDC 读取的是 MySQL binlog,相比“高频扫表做增量”,一般更轻量。但你仍需要关注 binlog 保留、磁盘空间、以及同步延迟等指标。正确配置与监控下,CDC 通常可以在生产稳定运行。
Snowflake 支持实时同步/准实时入仓吗?
Snowflake 支持多种准实时入仓模式(例如通过流式生态、连接器、持续加载等)。但端到端“有多实时”取决于你的链路设计、缓冲策略、失败重试与去重幂等等工程细节。
用 updated_at 做增量同步,怎么避免漏数/漏删除?
批量增量最容易踩坑的是:晚到更新、updated_at 不可靠、删除语义丢失、重复写入等。要稳妥需要水位线设计、幂等 upsert、删除补偿机制、以及补数策略。若你对一致性要求高,通常更建议基于日志的 CDC。
Debezium 这类开源 CDC 能不能做?CloudCanal 有什么优势?
开源 CDC(如 Debezium,常与 Kafka Connect 搭配)确实能实现 MySQL 变更捕获,但你需要自行负责部署、升级、监控告警、Schema 演进、故障恢复与 on-call 运维。CloudCanal 更偏向“生产可用的一体化迁移/同步任务”,把全量快照、增量 CDC、任务运维与可观测能力集中在一个平台里,降低落地与长期维护成本。
下一步建议
准备上生产前,先把下面 4 件事明确下来:
- 允许的停机窗口(如果必须不停机,就直接按 CDC 方案设计)
- 数据新鲜度目标(小时级/分钟级/更低)
- 关键表的一致性要求(删除、更新、幂等、唯一键)
- 运维归属(谁负责告警、重试、Schema 变更、补数)
如果您选择采用CDC方案,推荐您免费试用CloudCanal。在试用或操作过程中遇到任何问题,欢迎随时联系我们,我们会为您提供专业的技术支持。