Redshift 增量同步到 MySQL 实战(反向ETL教程)

Reverse ETL(反向ETL) 是一种将数据从数据仓库同步回业务�系统的数据集成模式。与传统 ETL “业务库 → 数仓” 不同,Reverse ETL 更强调把已经建模、聚合、治理后的数据重新下发到业务系统中。这种模式也常被称为“数据回流”“数仓回写”或“数仓数据下发”。
本文聚焦一种典型的反向 ETL 场景:将 Amazon Redshift 中的数据增量同步到 MySQL,实现“数仓 → 业务数据库”的数据回流。借助 CloudCanal 定时扫描,你可以按固定周期稳定运行一条 Redshift → MySQL 数据管道,让 MySQL 持续获得来自数仓的最新数据,而无需额外维护复杂的 CDC 链路。
本文会带你完成一次端到端配置,搭建 Redshift 到 MySQL 的反向ETL 任务:
- 将 Amazon Redshift 和 MySQL 接入为数据源
- 创建一个定时扫描同步任务
- 通过时间戳类型的增量字段开启增量同步
- 配置关键参数,让 Redshift → MySQL 同步在生产环境更稳定
什么时候适合用定时扫描做反向ETL?
当你要做 Redshift → MySQL 的增量同步,并且满足以下情况时,定时扫描是非常合适的选择:
- 你希望 运维模型尽可能简单(按计划扫描,然后写入 MySQL)。
- 允许存在一定延迟(例如每 5 分钟刷新一次)。
- 源端表有可靠的 时间戳字段 可用于增量读取(例如
updated_at)。
CloudCanal 里的 “定时扫描” 是什么?
CloudCanal 定时扫描(反向ETL) 是一种典型的 Reverse ETL(反向ETL)实现方式:系统会按固定周期扫描原端数据,并把扫描结果写入目标端。它适用于:
- 源端系统无法做 CDC(或不值得维护 CDC)。
- 需要按可预测节奏刷新(每隔 N 秒或 N 分钟)。
- 允许分钟级延迟的“准实时”同步场景。
如果你需要完整的界面操作流程,请继续往下看。
定时扫描如何实现 Redshift → MySQL 增量同步
定时扫描支持设置 增量字段:
- 增量字段是一个 时间列,可以理解为游标。
- 每一轮扫描时,系统会读取增量字段值 晚于上一次成功扫描结束时间 的数据行,并把这些行写入 MySQL。
一个重要限制:基于增量字段的扫描 无法捕获 Redshift 的硬删除。因为数据被删除后,源表中已经不存在对应记录,也就没有可扫描的数据。
在 Reverse ETL / 数据回流场景里,处理“删除”通常有以下几种方式:
- 软删除:增加
is_deleted或deleted_at字段,并�将其纳入增量同步。 - 全量同步:对于小表,可以使用 清空对端(每轮扫描前先清空目标端表),让 MySQL 变成 Redshift 的周期性快照。
开始前检查清单(Redshift → MySQL 反向ETL)
- 在 Redshift 里选定 增量字段(通常是
updated_at或摄取时间戳)。- 它需要可排序、可比较,并且在你关心的每次变更发生时都会被更新。
- 决定目标端 MySQL 的数据形态:
- 增量镜像(快,但无法反映硬删除),或者
- 周期性快照(每次扫描全量同步并配合清空对端)。
- 扫描间隔先保守一些,稳定后再逐步缩短(300 秒是一个实用的起点)。
逐步配置:创建 Redshift → MySQL 的定时扫描同步任务
如果你在连接 MySQL 时遇到权限错误,请先核对 MySQL 数据源所需权限:MySQL 数据源所需权限。
步骤 1:安装 CloudCanal
如果你还没有安装 CloudCanal,请前往 CloudCanal 官网,点击首页上的 “免费社区版” 按钮下载安装:
步骤 2:添加 Redshift 和 MySQL 数据源
- 安装完成后,访问本地控制台
http://${ip}:8111,使用以下信息登录:- 账号:
test@clougence.com - 密码:
clougence2021 - 验证码:
777777
- 账号:
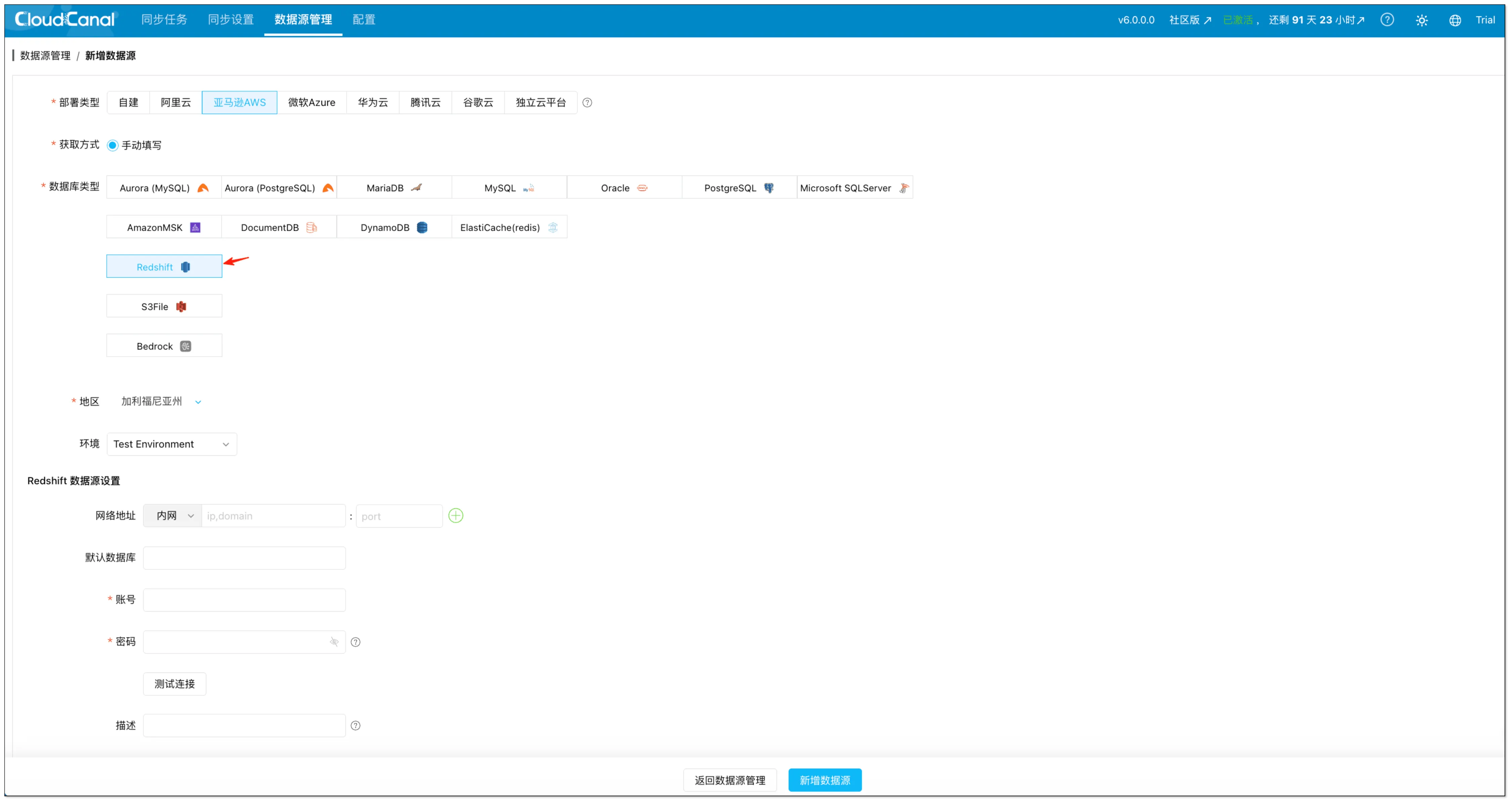
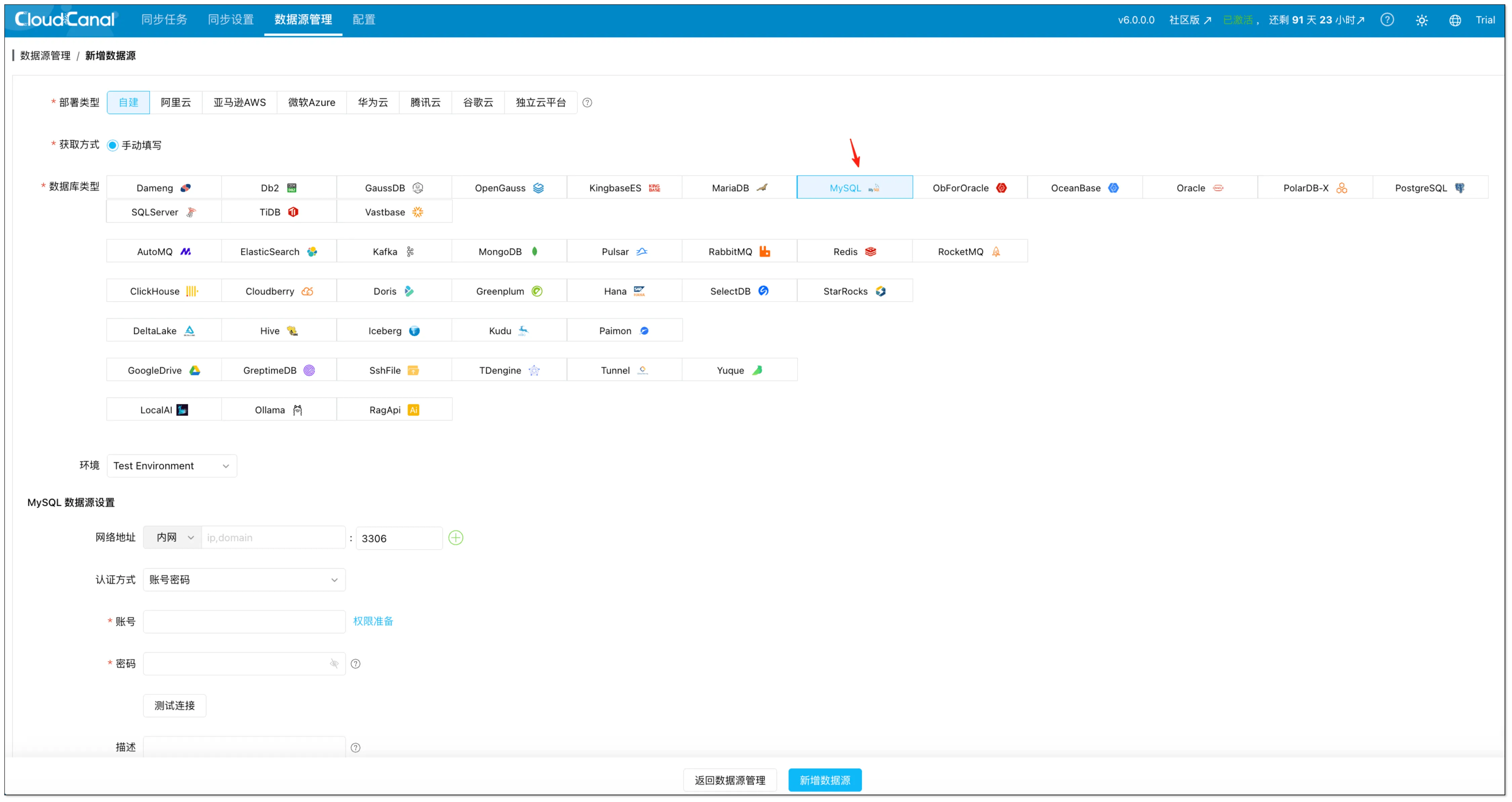
- 进入数据源管理→新增数据源。
- 分别添加 Redshift(源端)与 MySQL(目标端)作为数据源,并分别点击测试连接验证连通性。
步骤 3:配置同步任务(定时扫描 / rETL)
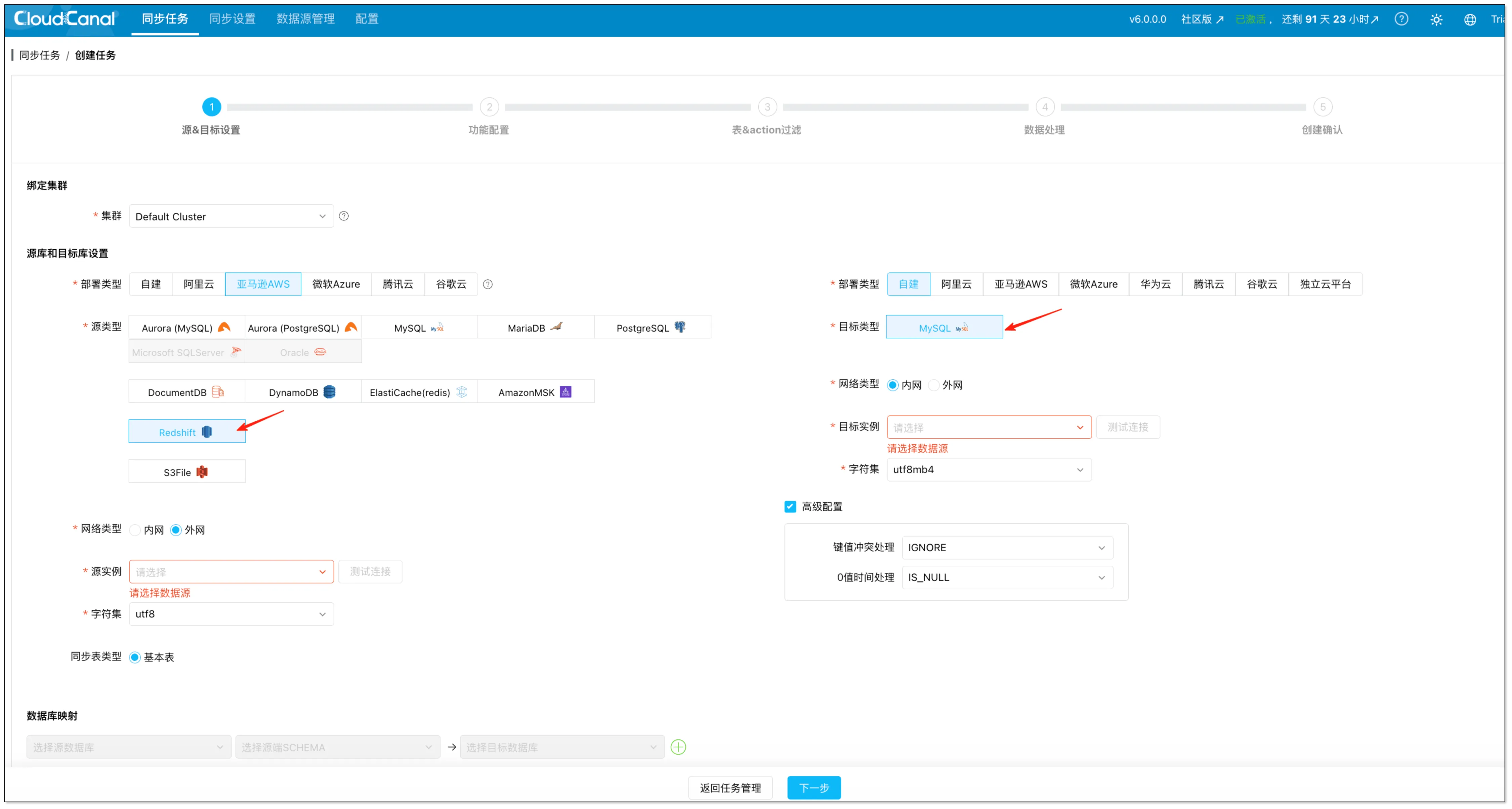
- 数据源添加完成之后,进入同步任务,开始创建一个新的任务。
- 选择 Redshift 作为源端、MySQL 作为目标端,按提示填写连接与同步相关信息后进入下一步。
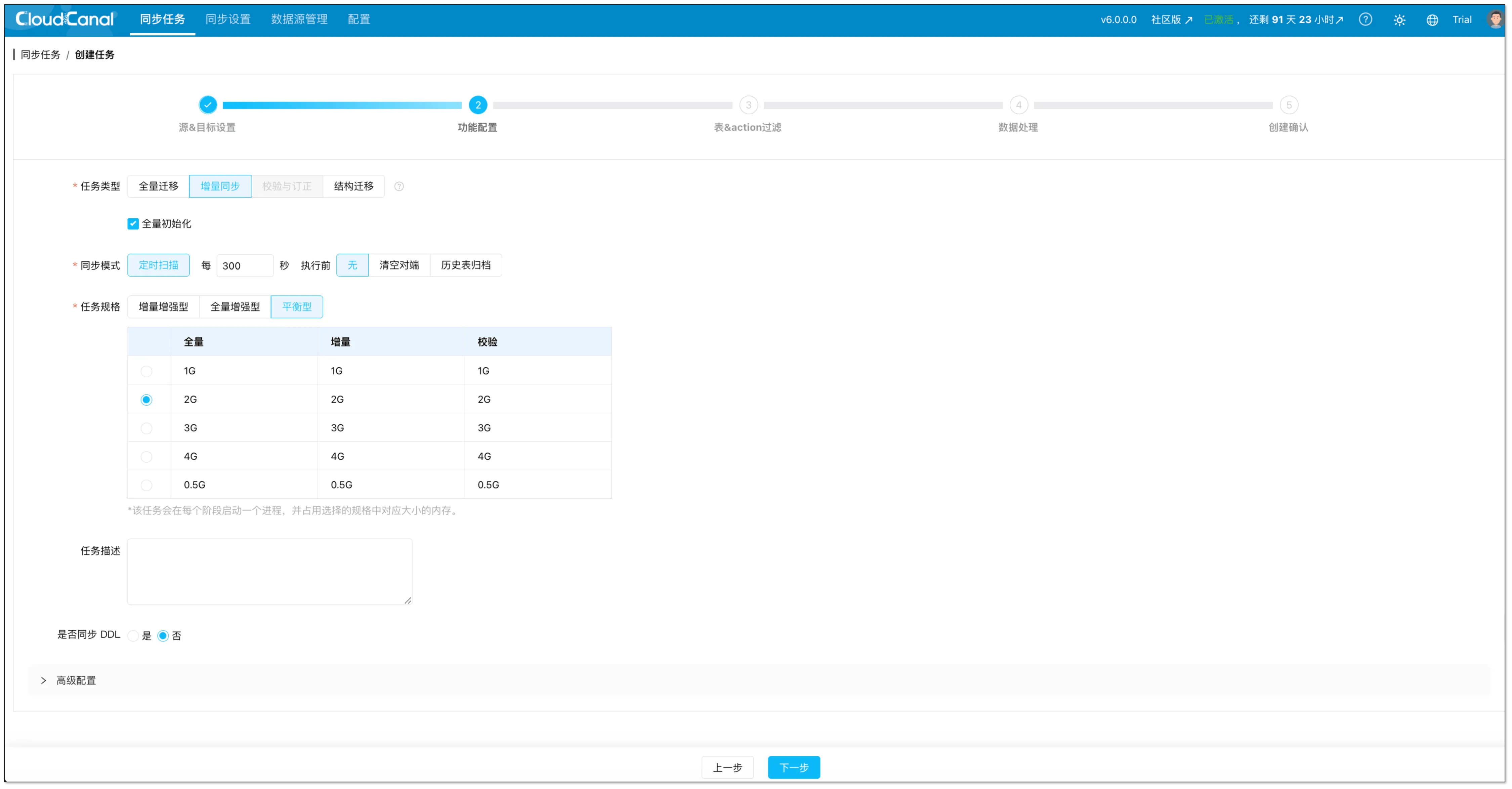
- 在功能配置页面,任务类型选择增量同步,同步模式选择定时扫描。
- 配置关键参数:
- 执行周期:扫描执行的频率(默认 300 秒)。
- 执行前动作:
- 如果你要通过增量字段做增量同步:选择无。
- 如果表较小,并且需要复制源端的删除操作,则数据处理页不选择增量字段,且此处选择清空对端。
步骤 4:选择需要同步的表
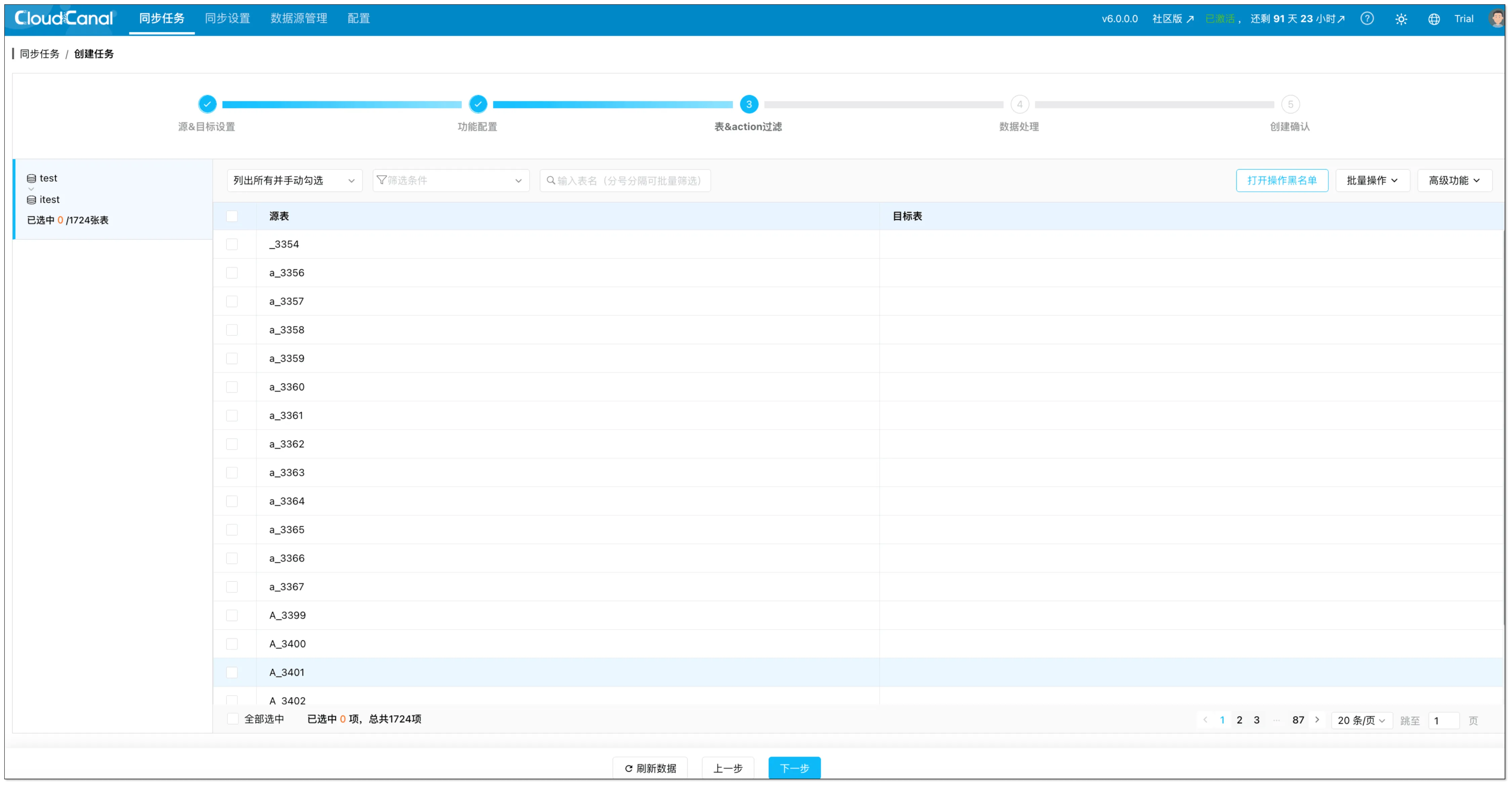
- 在表&action过滤页面,选择需要从 Redshift 同步到 MySQL 的表。
- (可选)如果你需要过滤特定操作,可使用打开操作黑名单。
步骤 5:配置增量字段(增量同步的关键)
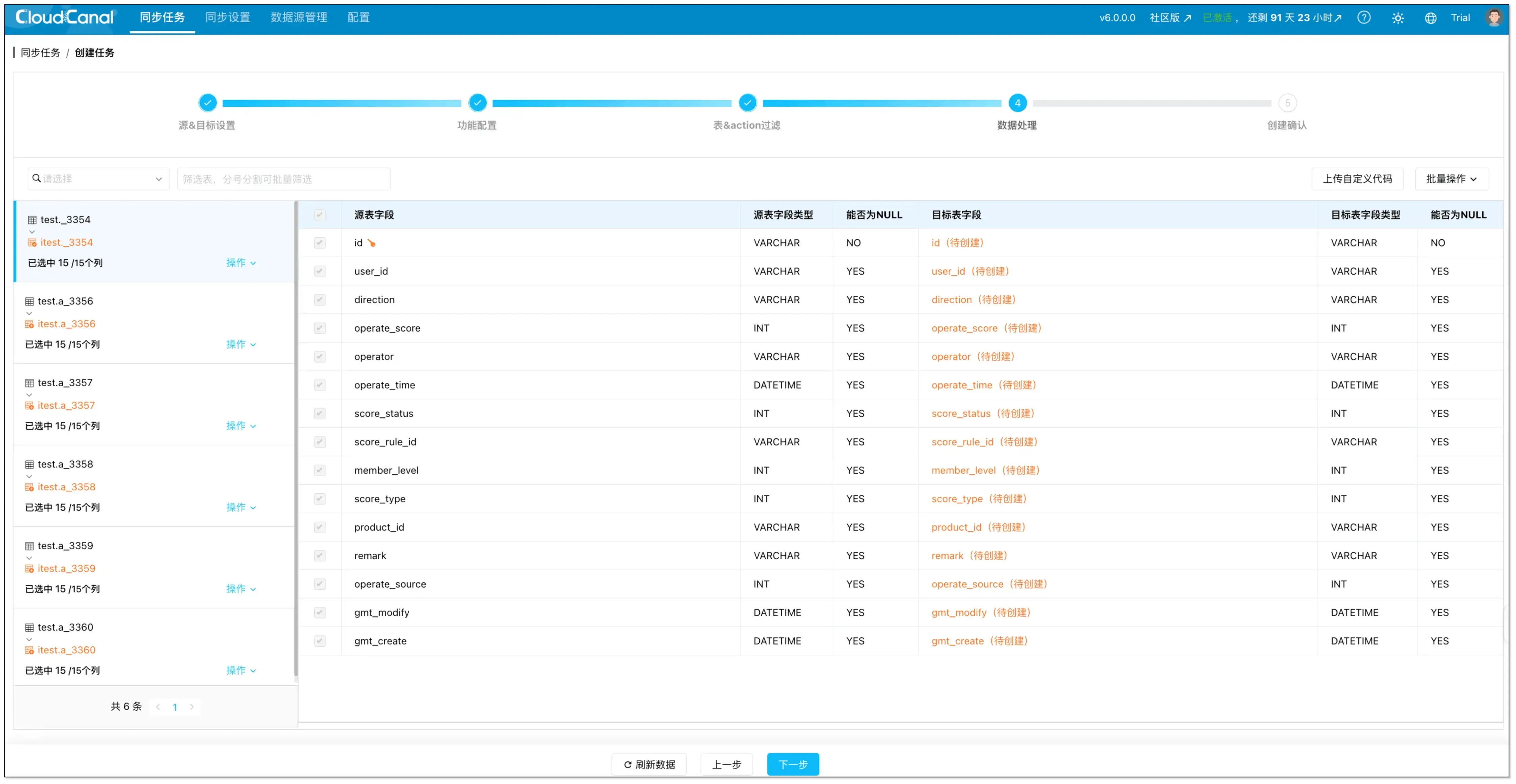
- 在数据处理页面,选择需要迁移的列。
- 配置增量字段:
- 单表设置:点击操作 → 增量字段
- 批量设置:点击批量操作 → 增量字段
如果你不配置增量字段,任务会在每个周期执行一次全表扫描,本质上更接近“周期性快照刷新”。
步骤 6:确认并创建
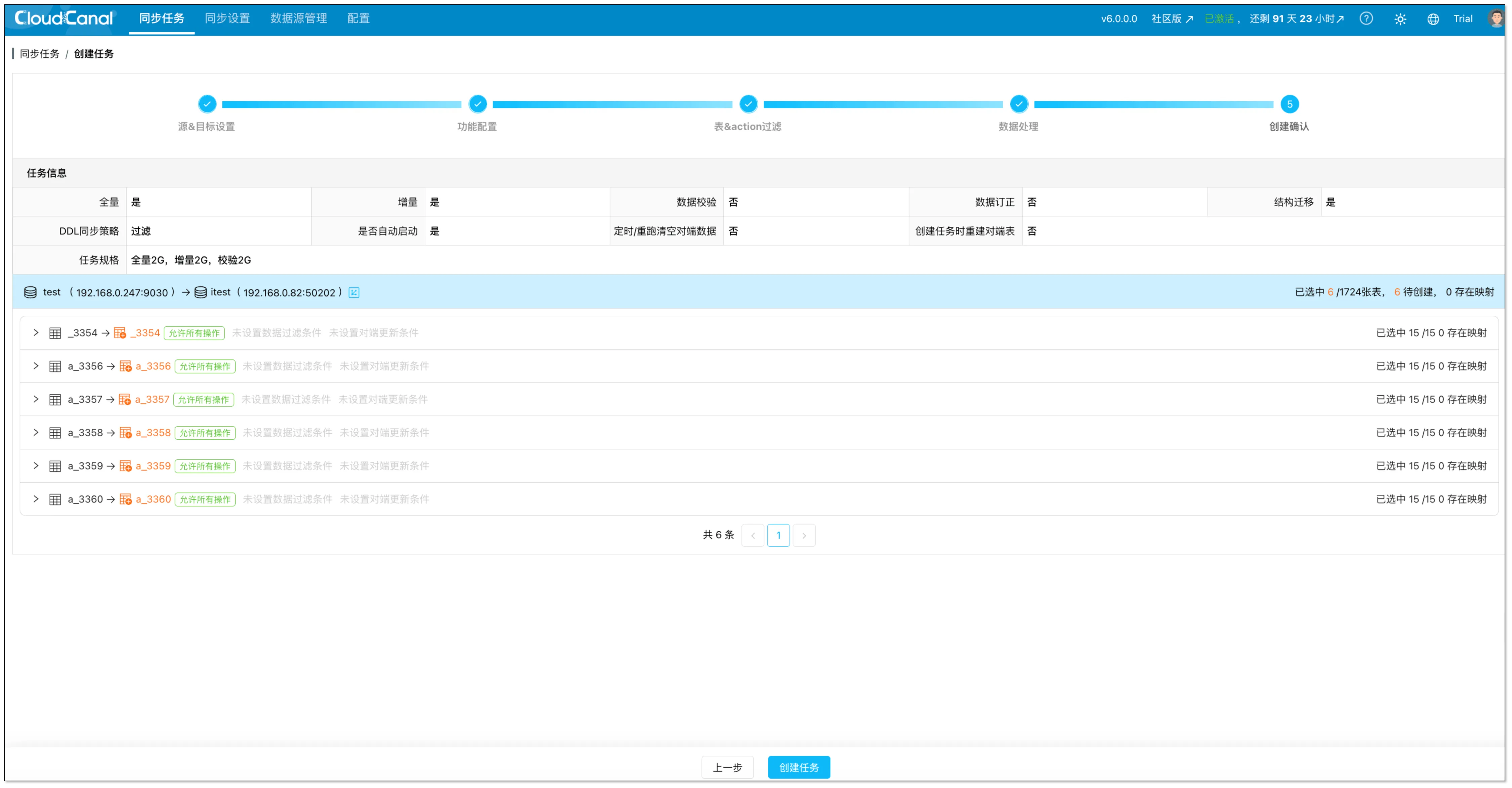
- 在创建确认页面核对配置。
- 确认无误之后,点击创建任务。
推荐配置:让 Redshift → MySQL 的反向ETL更稳定
下面这些设置能让 Redshift → MySQL 的增量同步更稳定、也更易运维。
执行周期
- 建议先从 300 秒 开始,待链路稳定后再逐步降低。
执行前动作
- 增量反向ETL(配置了增量字段):选择无。
- 每轮做周期性快照刷新:选择 清空对端,并不配置增量字段。
增量字段的选择原则
建议选择满足以下条件的时间列:
- 每次相关变更都会更新(不仅仅是插入(INSERT)时更新)。
- 在你的业务场景里具有足够的单调性(同一时间点大量更新时,避免使用精度不足或语义不清的时间戳)。
- 时区与语义一致(尽可能使用 UTC 存储)。
常见问题与排障(Redshift → MySQL 增量同步)
增量同步漏同步(更新没同步过去)
大多数情况下,根因都在增量字段:
- 更新(UPDATE)时没有更新该字段。
- 时间来源的时区/精度不一致。
- 字段可能为 NULL,或在行之间不具备严格可比性。
修复建议:确保 updated_at(或你选择的时间字段)在应用/ETL 层面被可靠维护,任何需要下发到 MySQL 的变更都能触发它更新。
Redshift 里删除了数据,但 MySQL 没有删除
这属于增量字段扫描的预期行为:硬删除无法通过扫描现有行发现。
可选方案:
- 改为软删除,并把删除标记/删除时间纳入增量同步。
- 对于需要镜像删除且表规模较小的场景,改用 清空对端 做周期性全量同步。
同步数据看起来正确,但下游读到的数据不稳定
这通常是建模/消费��侧的问题,建议:
- 为目标端设计独立的 schema(模式)/表命名规范。
- 如果你的服务架构支持,可以先同步到“影子表”(用于隔离正式业务读流量的临时同步表),再在应用层做切换/映射。
上游“晚到”的更新没有按预期出现在 MySQL
如果上游是批处理写入 Redshift,那么某些更新可能会在一次定时扫描之后才落入 Redshift。
可选方案:
- 增大扫描间隔,使其匹配上游批处理节奏。
- 确保增量字段表达的是你真正关心的 业务更新时间(而不是更早的事件时间)。
常见问答
为什么同步任务里没有 “增量字段” 选项?
可能原因包括:所选管道不支持增量字段,或所选字段类型不被该管道支持。对于 Redshift → MySQL 的定时扫描,增量字段的类型需要是 时间戳。
不配置增量字段,还能做 Redshift → MySQL 同步吗?
可以。不设置增量字段时,这个任务会变成周期性全表扫描/刷新(更像快照刷新)。
如何确认 Redshift → MySQL 任务运行在定时扫描模式?
在同步任务列表与详情页中,定时扫描任务会显示一个独特的“时钟”图标,便于快速识别同步模式。
Redshift 同步 MySQL 一定要 CDC 吗?
不需要。定时扫描是一种基于扫描的反向ETL方案:按计划从 Redshift 读取数据,并写入 MySQL。