StarRocks 源端全量迁移并行读取数据
· 阅读需 3 分钟

简述
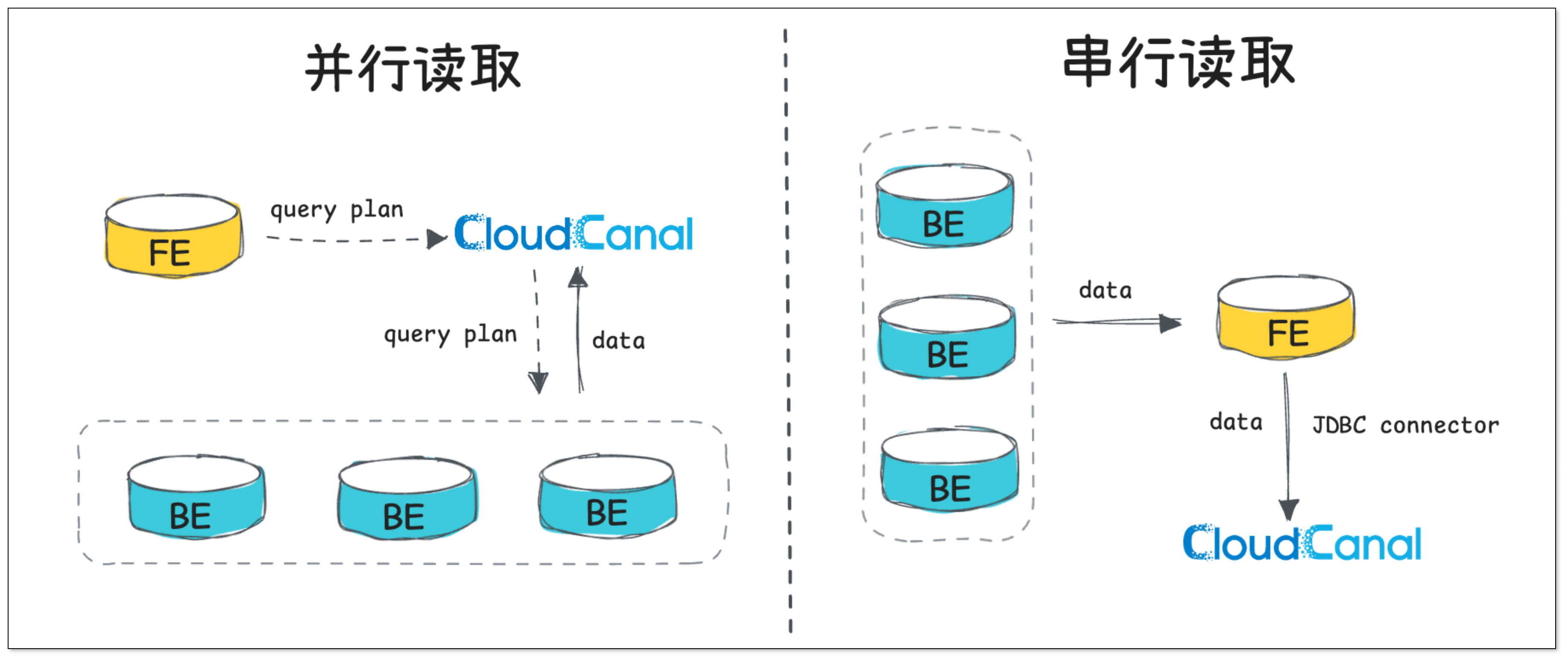
CloudCanal 近期支持了 StarRocks 源端全量迁移时从各 BE 节点并行读取数据的能力,相较于常规的单点数据串行读取,大大提高了数据读取效率及稳定性。
技术点
并行读取 BE 节点数据
CloudCanal 先从 FE 节点获取查询计划 (Query Plan),得到分片元数据信息,然后将获取到的分片元数据信息作为参数,下发至 BE 节点,最后获取 BE 节点返回的数据。
相较于常规的 FE 单点数据串行读取,并行读取有两点比较明显的优势,一是大幅提高效率,二是单次查询可控,避免单次查询数据量过大,导致 BE 节点内存溢出。
BE 节点级别的断点续��传
CloudCanal 会记录每个 BE 节点是否已读取完成。当任务失败或者中断后重启时,CloudCanal 可以过滤已经读取完成的 BE 节点,继续读取数据。
操作示例
步骤 1: 安装 CloudCanal
请参考 全新安装(Docker Linux/MacOS),下载安装 CloudCanal 私有部署版本。
步骤 2: 添加数据源
-
登录 CloudCanal 控制台,点击 数据源管理 > 新增数据源。
-
数据库类型选择 StarRocks,并填写 Client 地址和认证信息。
-
配置 额外参数:
参数 描述 feHttpAddr StarRocks FE 节点的 HTTP 地址,用于 CloudCanal 获取查询计划。例如,feNode:8030。 beThriftAddr StarRocks BE 节点的 Thrift Server 端口。因为查询计划中得到的节点信息是 Thrift Server 的内网端口,当 CloudCanal 无法直接访问时,需要提供可访问的所有 BE 节点 Thrift Server 端口。例如,beNode1:9060,beNode2:9060... -
按照上述步骤,添加目标端数据源。
步骤 3: 创建任务
-
点击 同步任务 > 创建任务。
-
配置源和目标数据源,并分别点击 测试连接。
-
选择 数据同步 并勾选 全量初始化,取消勾选 自动启动任务。
-
选择表对应的列。
信息如果需要选择同步的列,可先行在对端创建好表结构。
-
点击 确认创建。
-
进入任务详情页,点击 功能列表 > 修改任务参数,配置任务相关参数。
参数 描述 scanModel StarRocks 源端全量迁移扫描模式,需将参数值设为 DYNAMIC。 feHttpAddr StarRocks FE 节点的 HTTP 地址,用于 CloudCanal 获取查询计划。 beThriftAddr StarRocks BE 节点的 Thrift Server 端口。例如,beNode1:9060,beNode2:9060...(无法访问 StarRocks 内网时的备用方案)。 keepAliveMin StarRocks 查询任务的保活时间(单位:分钟),默认为 10 min。 queryTimeout StarRocks 查询任务的超时时间(单位:秒),默认为 600s,数据量大的时候需要调大该参数。 memLimit StarRocks BE 节点中单个查询的内存上限(单位:MB),默认为 1024 MB。 -
点击 同步任务。选择对应的任务,点击 启动。
-
等待全量任务完成。