Oracle 数据同步,用这种方式更安全

在 Oracle 实时同步场景中,如果默认连接生产主库,LogMiner 解析 redo 的过程可能会带来额外资源开销。
特别是对��于 CRM、ERP 等核心业务系统来说,主库本身已经承载了大量业务读写。同步链路长期运行,很可能会对生产库性能产生影响。
因此,很多团队进一步考虑:能不能不连主库,而是改连 Oracle DataGuard 备库?
当然可以。
近期,数据同步工具 CloudCanal 围绕 Oracle DataGuard 备库同步场景做了针对性优化,并已在用户生产环境中稳定运行。今天,我们将详细聊聊 Oracle DataGuard 备库同步的技术细节。
为什么不连主库?
对于数据量不大、同步表不多、链路数量有限的场景,直接连接主库往往是最简单的方案。配置少,路径短,延迟也更容易控制。
但在生产环境里,Oracle 实时同步的链路往往要 7x24 小时挂在生产库旁边。它可能要支撑实时报表、风控分析、数据湖入湖、搜索索引更新,也可能承担国产数据库迁移过程中的持续增量同步。
而这就带来了新的问题。
Oracle 增量同步链路,本质上还是要靠 LogMiner 读 redo,启动 LogMiner 会话,查询 V$LOGMNR_CONTENTS,并依赖数据字典解析 redo 中的对象、列和类型信息。
在业务高峰期、大事务、大表变更、RAC 多线程日志切换频繁的场景下,LogMiner 会带来额外的 CPU、I/O 和字典解析开销。而很多企业的 Oracle 主库本身已经足够繁忙。交易、订单、库存、财务这类系统对稳定性非常敏感,任何额外组件接入主库,都需要经过审慎评估。
在这些场景下,Oracle 实时同步需要平衡同步链路的稳定性和对生产主库的影响,这也是很多团队开始考虑 DataGuard 备库的原因。
用 DataGuard 备库做同步入口
CloudCanal Oracle DataGuard 备库同步的做法其实不复杂:业务写入还在主库,把 redo 解析放到备库。
主库继续处理业务写入,并按 DataGuard 机制传输 redo。备库接收 redo,生成并保留归档日志。CloudCanal 连接备库,基于备库的归档日志和 LogMiner 字典文件解析增量变更,再把数据写入目标端。
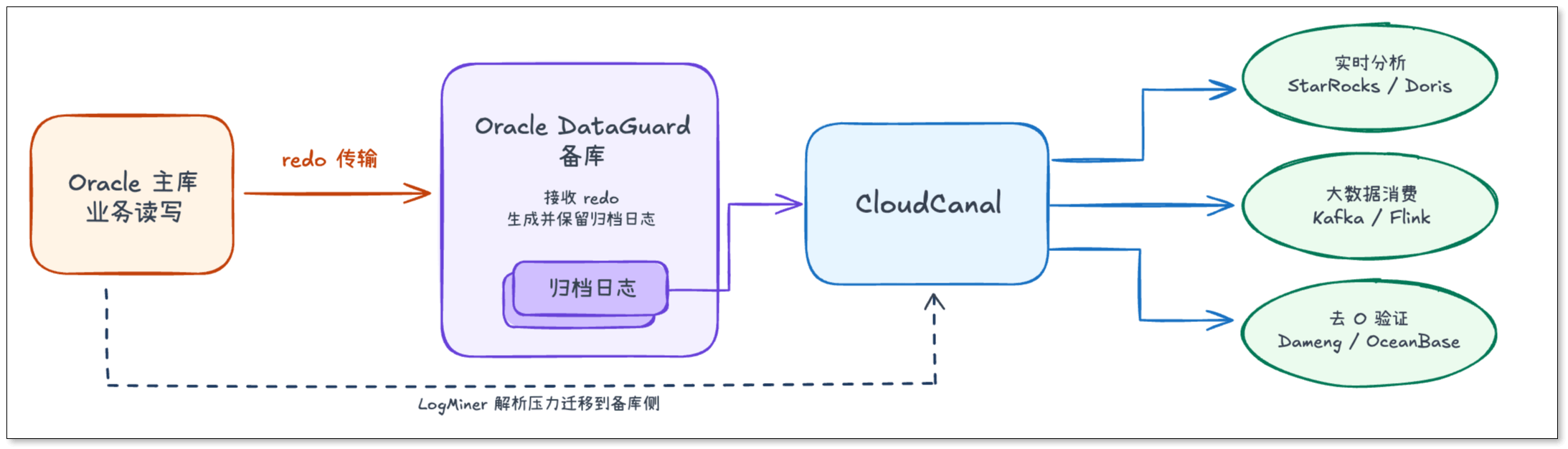
这样主库侧新增的长期解析压力就会减少很多,同步任务需要读取、解析等动作,都转移到了备库完成。
对 DBA 来说,同步链路不直接占用主库 LogMiner 解析资源,生产库更稳定。对数据团队来说,备库仍然能持续接收主库变更,满足下游对实时性的要求。
备库同步的挑战
把同步入口从主库切到备库,并不只是简单地改一个连接地址,在很多技术细节上需要做特别的设计。
下面结合数据同步工具 CloudCanal 在 Oracle DataGuard 备库同步实践中处理过的几个问题,展开讲讲如何解决 Oracle 备库同步过程中的常见问题。
归档日志怎么读?
在 DataGuard 场景中,CloudCanal 需要基于备库可见的归档日志解析增量。
相比在线 redo,归档日志已经落盘,SCN 范围明确,更容易稳定消费。因此,CloudCanal 在 DG 备库场景下默认启用 Archive-only 模式,只读取备库侧可见的归档日志,减少日志切换期间的读取不确定性。
在 RAC 场景中,问题会更复杂。Oracle RAC 可能有多个 redo thread。不同 thread 的 sequence 需要按正确顺序合并和解析,否则就可能出现重复读取、漏读,或者某个线程的 redo 没有被正确覆盖。
CloudCanal 会按 thread 和 sequence 合并归档日志,并检查日志范围,避免重复分析或漏掉某个线程的 redo。
多个归档目录怎么处理?
Oracle 备库可能配置多个本地归档目录,默认目录不一定包含同步任务需要的全部日志。如果同步工具只盯着一个目录,就可能在日志切换或归档策略调整后找不到日志。
CloudCanal 支持通过参数 archiveDestName 指定一个或多个归档目的地。对于备库配置了多套本地归档目录的环境,可以显式告诉任务从哪些位置读取日志,减少默认路径不匹配带来的风险。
archiveDestName=LOG_ARCHIVE_DEST_2
archiveDestName=LOG_ARCHIVE_DEST_1,LOG_ARCHIVE_DEST_2
字典怎么保持稳定?
LogMiner 需要数据字典才能把 redo 里的对象 ID 还原成表名、列名和字段类型。备库环境下如果字典来源不稳定,或者 DDL 发生后字典刷新不及时,就可能出现解析结果和真实表结构不一致的问题。
在 DG 备库模式下,CloudCanal 使用 Flat File 字典。通过 DBMS_LOGMNR_D.BUILD 生成字典文件,并在 LogMiner 启动时使用该文件进行解析。
这样做的好处是字典来源更明确,LogMiner 解析时不容易受到在线字典变化影响,也更适合备库环境。

如果源端 DDL 频繁,字典文件和实际表结构之间可能出现短时间不一致。
CloudCanal 支持按固定时间点或按小时间隔构建字典,同时在任务中维护表结构信息,辅助还原 LogMiner 输出结果。即使字典刷新存在时间差,增量数据也能被正确还原。
oraBuildRedoDicStrategy=INTERVAL_HOUR
oraBuildDicValue=4
任务中断后怎么恢复?
长期运行的同步链路一定要考虑恢复能力。同步任务升级、网络抖动、目标端故障、归档延迟都可能导致任务短暂中断。真正可用于生产的备库同步,需要自动记录消费到哪个 SCN,也要能在异常后从正确位置继续。
CloudCanal 会保存消费 SCN,任务重启后可以从断点继续。同时,CloudCanal 会检查起始 SCN 和 RAC 多线程日志范围。如果归档不连续,任务会明确报错,而不是静默跳过问题。
配合数据校验、订正和任务告警,备库同步链路不只是在正常情况下能跑,也能在异常发生后更容易恢复。
实操演示
下面以 Oracle 到 StarRocks 的实时同步为例,演示如何用 CloudCanal 实现 Oracle DataGuard 备库同步。
目标端也可以换成 Elasticserach、PostgreSQL、Kafka、MySQL 等十几种 CloudCanal 支持的数据源。
步骤 1:安装 CloudCanal
进入 CloudCanal 官网,点击 免费社区版。
参考 全新安装(Docker),一键安装 CloudCanal 私有部署版本。

安装完成后,用默认账号(test@clougence.com / clougence2021)登录控制台。
步骤 2:添加数据源
点击 数据源管理 > 新增数据源,填写以下信息,分别添加 Oracle 和 StarRocks。
添加 Oracle
- 部署类型:自建
- 数据库类型:Oracle
- 网络地址:填写连接 Oracle 实例的 IP 和 host
- 认证方式:选择合适的认证方式
DG 备库同步需要先完成备库侧准备,具体步骤可参考官方文档:Oracle 源端 DataGuard 备库配置。
然后修改以下额外参数:
| 参数 | 示例 | 说明 |
|---|---|---|
isDataGuard | true | 开启 DataGuard 备库同步模式 |
dgDicLocation | DIC_DIR | Flat File 字典使用的 Oracle DIRECTORY 名称 |

添加 StarRocks
- ��部署类型:自建
- 数据库类型:StarRocks
- Client 地址:填写连接 StarRocks 实例的 IP 和 host
- 认证方式:选择合适的认证方式
修改以下额外参数:
- privateHttpHost:修改为 FE/BE 节点的 IP 和 host

步骤 3:创建链路
点击 同步任务 > 创建任务,进入任务创建流程。
选择源端和目标端数据源,点击 测试连接。

在功能配置页面,任务类型 选择 增量同步,并勾选 全量初始化。

在表 & action 过滤页面,勾选要迁移的表。

在数据处理页面,勾选要迁移的列。

在创建确认页面,点击 创建任务。

CloudCanal 将自动开始运行任务,在任务列表可查看进度。

用在什么场景
DataGuard 备库同步通常可以用在主库负载敏感、已有 DataGuard 架构、又需要把 Oracle 数据持续送往异构系统的场景。
第一类是实时分析。企业会将 Oracle 中的订单、交易等数据同步到 StarRocks、ClickHouse、Doris 等分析型数据库,用于实时报表和经营看板。这类链路通常需要长期运行,直接从主库解析 redo 容易让 DBA 有顾虑,如果解析压力落在备库,DBA 通常更容易接受。
第二类是大数据消费。Oracle 变更进入 Kafka 后,可以继续被 Flink、湖仓、风控、推荐等系统消费。一个 Oracle 源端往往会服务多个下游系统,每多一个消费方,主库的压力都会持续增加;而 DataGuard 备库作为同步入口,可以把主库和下游消费体系解耦,避免同步压力持续叠加到主库。
第三类是去 O 迁移和国产数据库验证。企业会将 Oracle 核心表同步到 Dameng、OceanBase、openGauss、KingbaseES 等目标库,用于迁移验证、双跑比对和阶段性切换。这类迁移项目常常需要持续运行几个月,对稳定性要求高,中间不能因为同步工具影响原业务。
总结
DataGuard 不只是 Oracle 的容灾资源,也可以成为实时同步链路中的稳定入口。
当主库负载敏感、下游系统较多、同步链路需要长期运行时,从 DataGuard 备库读取增量,通常比直接连接主库更稳妥。
CloudCanal 针对 Oracle DG 备库同步场景,在 Archive-only 归档读取、多归档目的地、Flat File 字典、定期字典构建、SCN 位点恢复等方面做了持续优化,保障了备库增量解析的稳定性。
如果你已经在 Oracle 实时同步上遇到主库压力问题,或者正在规划去 O 路线、需要长期稳定运行同步链路,可以试试这个方向。