某电商服务商如何在 5000 TPS 持续写入下实现实时数据同步

背景介绍
某国内头部电商运营服务商提供全周期客户服务与营销自动化服务,长期服务于各类电商品牌企业。
围绕电商履约与售前、售后场景,该公司构建了一整套自动化解决方案,包括物流自动化能力、智能工单系统,以及与 ERP 等业务系统的一站式集成。通过将复杂、分散的业务流程系统化、自动化,帮助企业提升履约效率,降低物流与人工成本,同时持续改善消费者体验。
在这样的业务定位下,该公司不仅需要处理来自多个电商平台的大规模订单与物流数据,还需要将这些数据实时分发给不同的业务系统使用,这对底层数据架构提出了更高要求。
业务背景
该电商服务商的核心业务,建立在高并发、强实时的数据之上。
以物流自动化场景为例,系统需要实时识别并处理“已发货仅退款”等复杂情况,及时拦截不必要的物流动作,节省物流成本;同时自动识别异常物流状态,及时提醒客服人工介入,提高处理效率。
这些能力的实现,高度依赖稳定、低延迟的数据流转。来自淘宝、天猫、京东等平台的数据通常会实时写入 MySQL 或 PostgreSQL 的推送库中,日常数据写入量约为 4000–5000 TPS。该公司的数据团队需要在极短时间内,将这些变更数据同步至内部消息系统 RocketMQ,供物流查询、订单系统、客服工单等多个下游系统并发消费。
在这一背景下,数据延迟会直接影响用户满意度。一旦延迟超过 10 分钟,就会产生上百万条数据积压,大量用户将无法查询最新物流动态,导致客服咨询量激增,严重影响服务口碑。尤其在双 11、618 等大促期间,瞬时流量洪峰可达日常 3 倍以上,对数据同步的稳定性、实时性提出了更高的要求。
原有方案与痛点
早期,该公司采用自研代码直接读取源库数据并进行处理。这种方式在初期开发成本低、上线快,但随着业务规模扩张,问题逐渐显现:
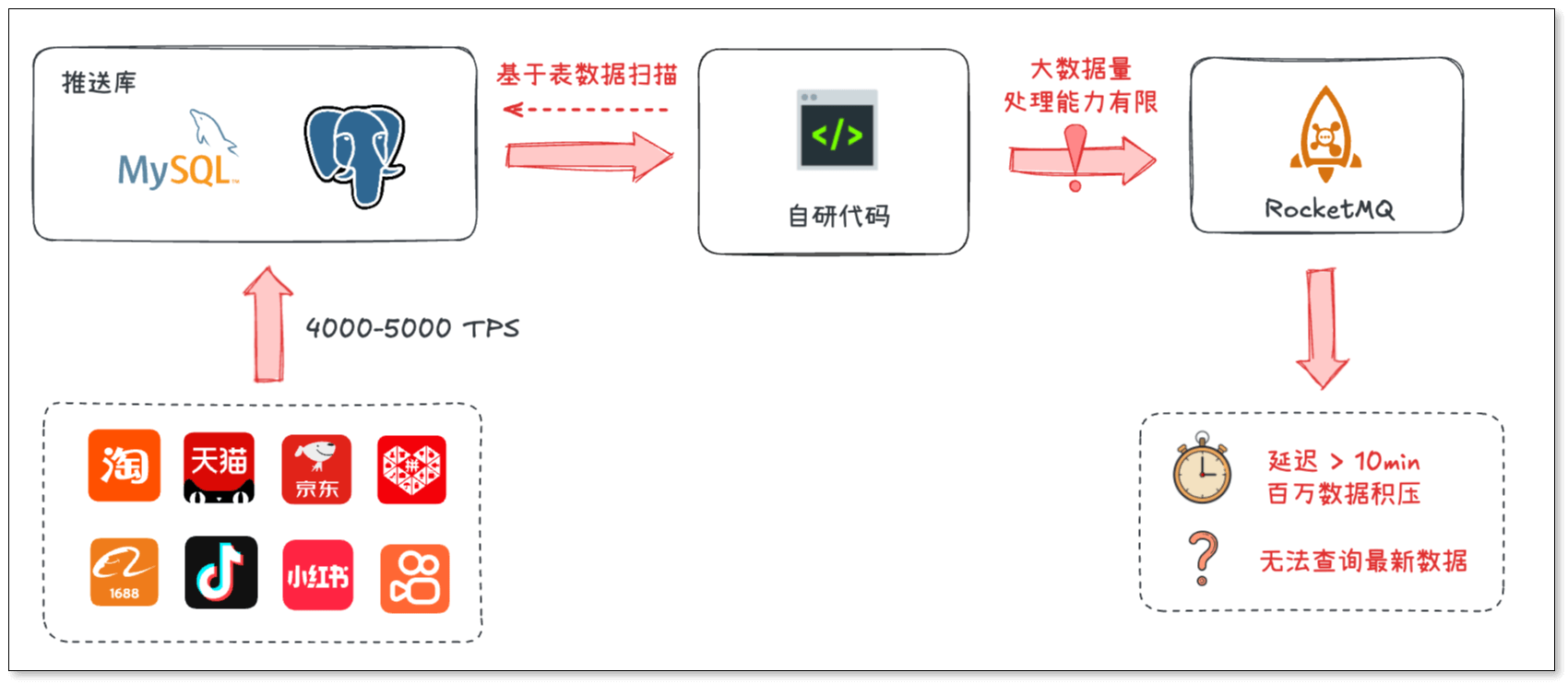
- 源库压力过大:直接读取源库数据,影响核心业务系统稳定性。在高峰时段容易引发性能抖动,甚至影响前端交易系统的稳定性。
- 处理能力有限:当数据量突增时,同步和消费速度跟不上生产速度,消息队列积压,严重影响用户端使用体验。
- 扩展性不足:面对流量增长,只能通过增加服务器数量来横向扩容,但代码层面缺乏弹性调度机制,新增节点后负载均衡效果差,难以长期持续。
- 运维负担重:需要专人监控同步任务状态,处理断点续传、位点丢失、DDL 兼容等问题,人力投入大。
很明显,这套自研方案已经难以支撑高并发、低延迟、长期稳定运行的生产需求。因此,该数据团队开始寻求一套更专业可靠的解决方案。
数据架构升级
在多轮技术评估与 POC 验证后,该电商服务商最终选择 CloudCanal 作为其核心数据同步组件,替代原有自研方案。
整体架构如下:
MySQL / PostgreSQL(推送库)→ CloudCanal → RocketMQ → 下游业务系统
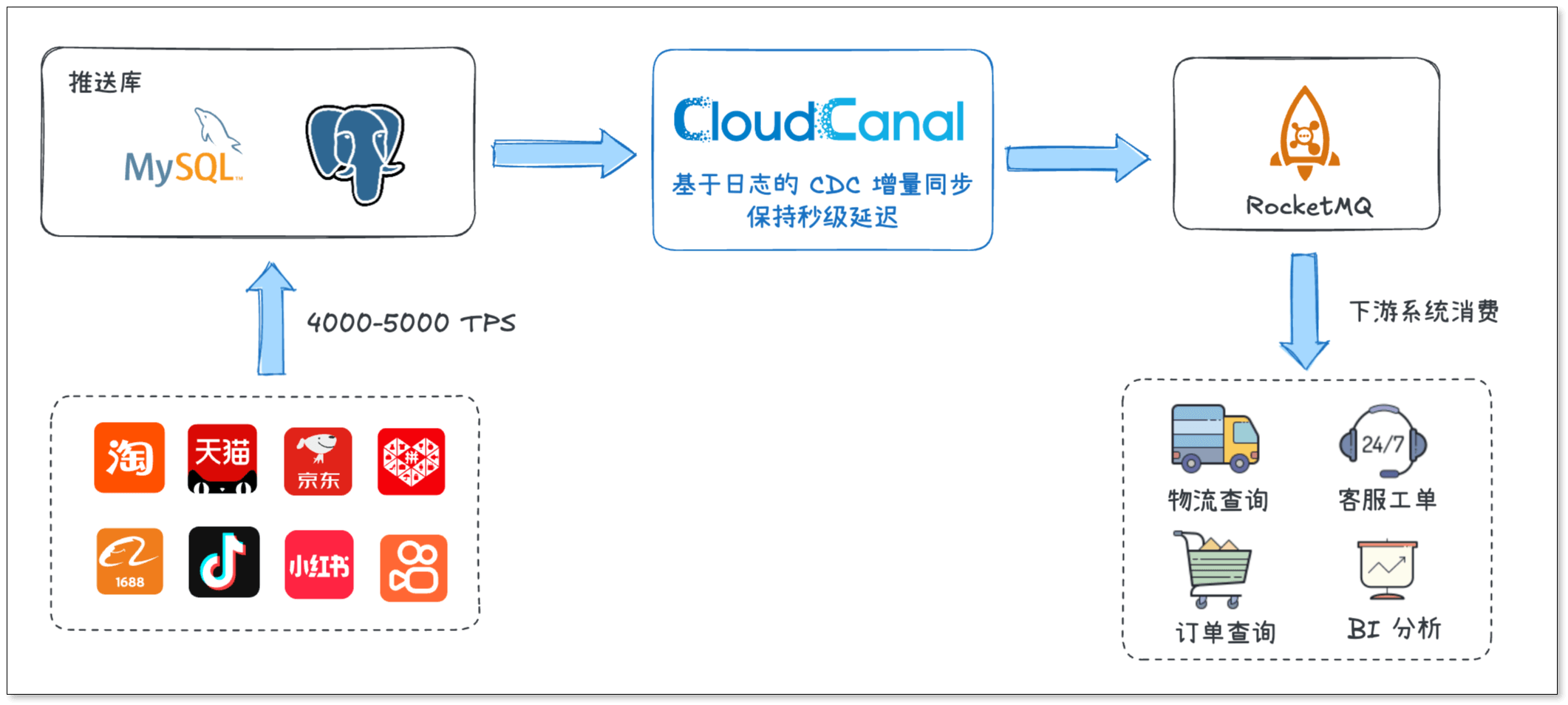
这一架构实现了源库与下游系统的解耦,源库压力明显降低,下游系统也可以通过消息方式按需消费数据,为后续业务扩展提供了更大的灵活性。
为什么选择 CloudCanal
在该公司的业务体系中,数据同步主要服务于物流查询、订单状态和工单处理等在线业务,无论是上游数据来源,还是下游消费系统,都是 7×24 小时运行的在线系统,这就要求数据同步工具需要在不影响源库性能的前提下,实时、稳定地向下游系统输出准确、完整的数据。
传统 ETL 工具的局限
在评估过程中,该数据团队发现许多面向离线分析或大数据处理的同步工具,更偏向批量抽取或准实时处理,通常依赖定时任务、全表扫描或对源库进行较重的查询操作。在高并发在线业务下,这类方案要么对上游数据库产生明显压力,要么难以在高写入量下保证数据的实时�性与稳定性,很难同时满足“影响小、数据准、延迟低”的要求。
CloudCanal 的综合解决方案
CloudCanal 作为专业的数据迁移与实时同步软件,其多项核心设计更贴合高并发在线业务场景:
- 对源库影响最小化:基于数据库变更日志同步数据,避免对源库进行额外扫描,从根本上降低了对上游数据库的影响。
- 实时同步:同步阶段仅同步增量数据,无需定时扫描全表,同步效率更高,在持续高并发写入的情况下也能保持秒级延迟。
- 数据准确、完整:同步过程中能够保持数据的顺序性和一致性,并且内置数据校验与订正功能,有效保障数据不重不漏。
- 稳定性高:支持断点续传、异常恢复、故障自动切换等机制,即使在短暂异常后,也能保证数据按顺序、无丢失地继续同步。
- 维护成本低:提供零代码、可视化的配置界面,并具备完善的运行状态监控和告警能力,让同步链路的运行状态更加可观测、可维护。
综合来看,CloudCanal 在同步机制、实时性、可靠性等方面的表现,非常符合该公司在线业务对时效性和稳定性的要求,因此成为其核心数据链路中的重要组成部分。
效果与价值
稳��定运行超四年,零故障
CloudCanal 上线后,已在其生产环境中稳定运行 四年多。几十条数据同步链路在长期高流量情况下保持零故障,从未出现因同步异常导致核心业务受影响。由于超高的稳定性,运维成本也大幅降低,可将更多时间和资源用于业务逻辑优化。
长期保持秒级延迟
在日常业务负载下,数据从推送库产生变更到被下游系统消费,延迟基本稳定在秒级。
即使在双 11、618 等流量高峰期,整体延迟也能够控制在 1 分钟以内,避免了数据大规模积压,用户可以实时查询订单、物流和售后状态,客服系统也能够及时处理工单。
数据完整同步,零丢失
在数据处理能力方面,CloudCanal 稳定承载高 TPS 的变更流量,并确保数据完整性,实现零丢失。这为下游系统提供了可靠的数据基础,技术团队也不需要再额外处理缺失或重复数据的问题。
总结
在电商履约与售后场景中,实时、稳定的数据同步能力往往是影响用户满意度和购物体验的关键一环。
通过引入 CloudCanal,该电商服务商构建了一条高吞吐、低延迟、可持续扩展的实时数据通道,为复杂、高并发的业务场景提供了坚实支撑。这一实践,也为同样面临实时数据挑战的电商技术团队提供了可参考的思路。