分库分表数据汇聚
简述
CloudCanal 2.X 版本近期支持了自定义代码能力,带来了丰富的场景化数据能力,本文主要介绍在面向 To C 业务分库分表情况下,如何通过 CloudCanal 进行数据实时汇聚。
本方案特点:
- 数据处理灵活,适配多变的业务数据汇聚需求
- 针对大部分带结构数据源互通,可举一反三
- 稳定性较好
技术点
约束冲突
对于一部分分库分表中间件或业务自己写的拆分逻辑,并没有考虑写入数据主键或者唯一字段值的全局唯一问题,导致做数据汇聚时约束冲突。
另一类系统,在业务上就独立,做数据汇集时,除了约束冲突,还存在结构不一致,数据规范不统一的问题。
对以上两种情况,添加额外的字段以消除分表之间的约束冲突,进行数据清洗、结构调整,将数据进行规整。自定义代码能够很好的完成这种使命。
DDL 同步
分库分表数据汇聚还存在一个较大的问题是 DDL 同步,对于大部分这类场景, 类似的 DDL 会在源端执行多遍,但是在对端只能执行一遍,并且数据和部分 DDL 有顺序依赖问题 --- 只有 DDL 在对端执行成功之后,新的数据才能写入或者执行。
我们目前建议不同步 DDL, 按照一定规范进行源和目标端 DDL 变更,达到不延迟且 DDL 不处于中间状态的目的。
操作示例
前置条件:
下载安装 CloudCanal 私有部署版本,使用参见快速上手文档
准备好 MySQL 数据库(本例源端 5.7 ,目标端 8.0)
源端 MySQL 上创建 2 个分库( shard_1 和 shard_2), 表结构一致(本例每一个分库只有一张分表)
CREATE TABLE `shard_1`.`my_order` (
`id` bigint(19) NOT NULL AUTO_INCREMENT,
`gmt_create` datetime NOT NULL,
`gmt_modified` datetime NOT NULL,
`product_id` bigint(20) NOT NULL,
`user_id` bigint(20) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=35 DEFAULT CHARSET=utf8
CREATE TABLE `shard_2`.`my_order` (
`id` bigint(19) NOT NULL AUTO_INCREMENT,
`gmt_create` datetime NOT NULL,
`gmt_modified` datetime NOT NULL,
`product_id` bigint(20) NOT NULL,
`user_id` bigint(20) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=35 DEFAULT CHARSET=utf8目标 MySQL 上创建 1 个汇聚库(no_shard),并包含1张汇聚表
- 额外多出 region 字段,该字段通过自定义代码固定生成
- 源端主键 id 和生成字段 region 组合成联合主键,方便数据汇聚时保持唯一
CREATE TABLE `my_order` (
`id` bigint NOT NULL,
`region` varchar(64) NOT NULL,
`gmt_create` datetime NOT NULL,
`gmt_modified` datetime NOT NULL,
`product_id` bigint NOT NULL,
`user_id` bigint NOT NULL,
PRIMARY KEY (`id`,`region`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3
开发宽表代码
- 代码工程 cloudcanal-data-process ,并找到代码类 MySqlPartitionToMySql1_user_1.java 和 MySqlPartitionToMySql2_user_1.java
- 为了清晰,本案例对于不同的源库,使用不同的自定义代码,实际上两者逻辑一致,只是匹配库表是有所不同。
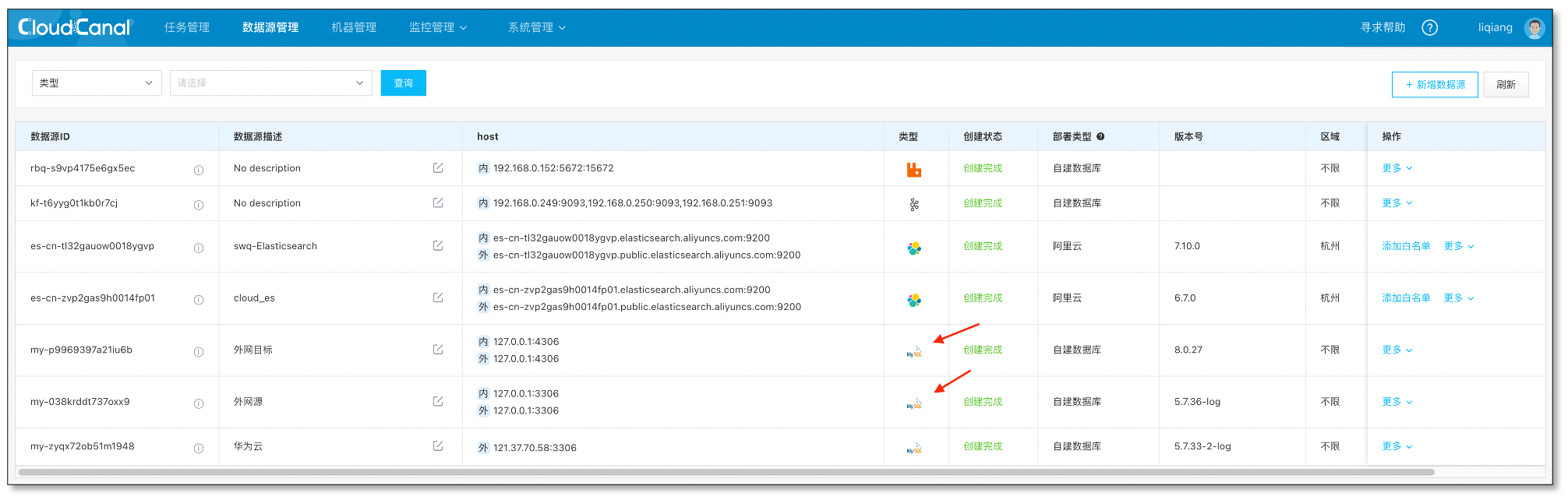
添加数据源
- 登录 CloudCanal 平台
- 数据源管理->新增数据源
- 将源端和目标端MySQL 分别添加
分库shard_1任务创建
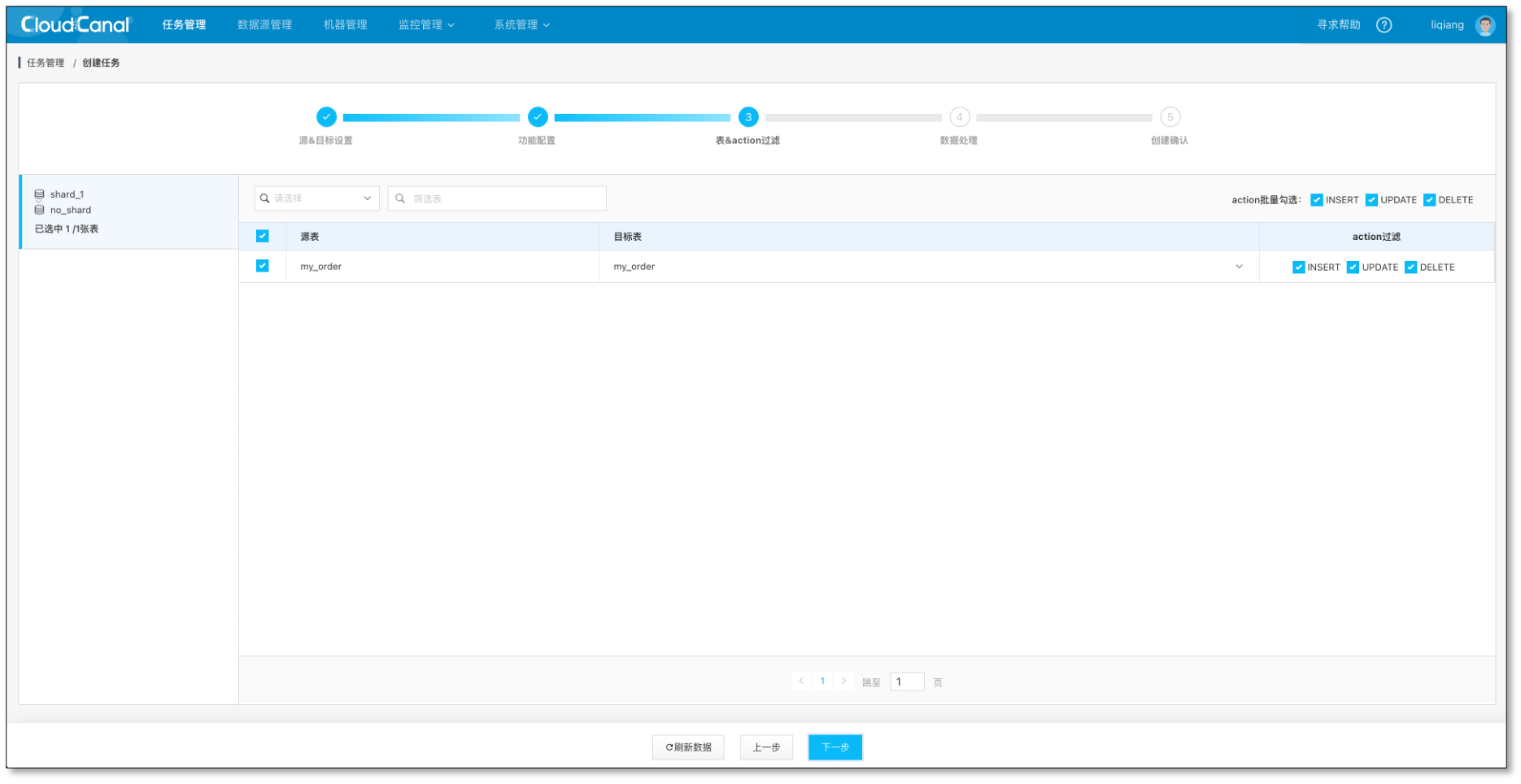
- 任务管理->任务创建
- 选择 源 和 目标 数据源
- 选择 数据同步,并勾选 全量数据初始化, 其他选项默认
- 选择需要迁移同步的表, 此处只要选择待聚合表即可,对端选择聚合表
- 修改自定义代码,并打包
% pwd
/Users/zylicfc/source/product/cloudcanal/cloudcanal-data-process
% mvn -Dtest -DfailIfNoTests=false -Dmaven.javadoc.skip=true -
Dmaven.compile.fork=true clean package
- 选择列,默认全选,选择上传代码包1
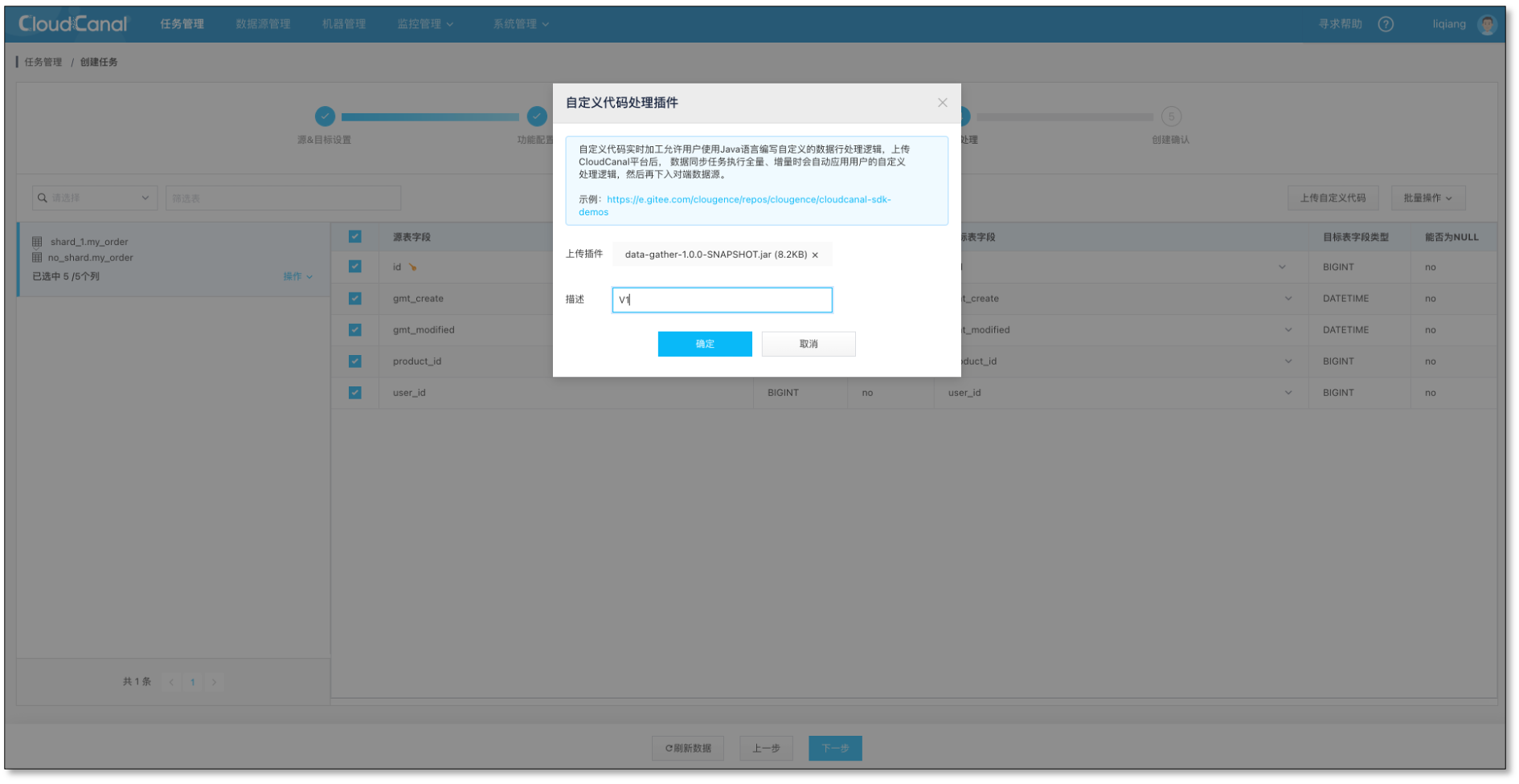
- 确认创建,并自动运行
分库shard_2任务创建
- 任务管理->任务创建
- 选择 源 和 目标 数据源
- 选择 数据同步,并勾选 全量数据初始化, 其他选项默认
- 选择需要迁移同步的表, 此处只要选择待聚合表即可,对端选择聚合表
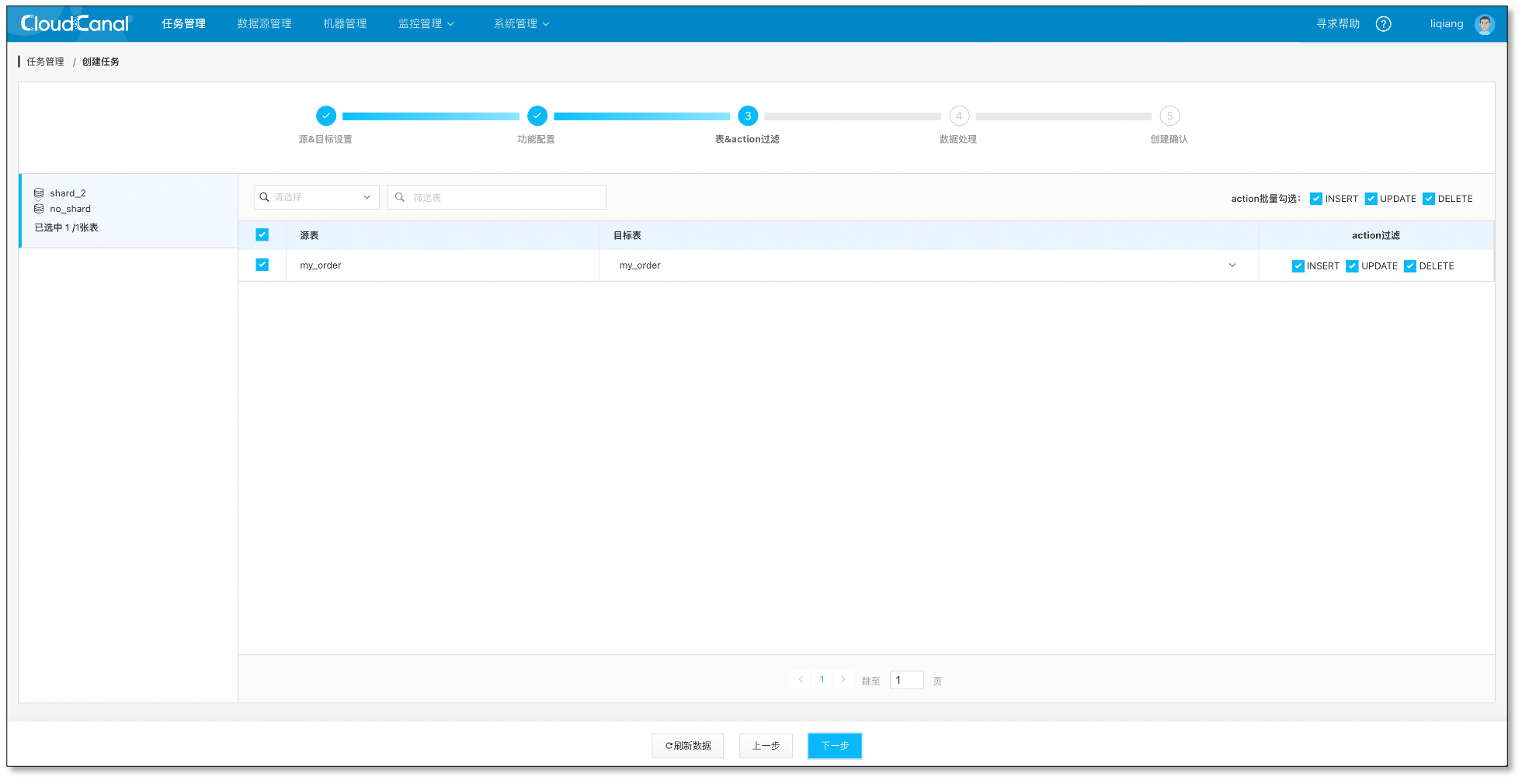
- 修改自定义代码,并打包
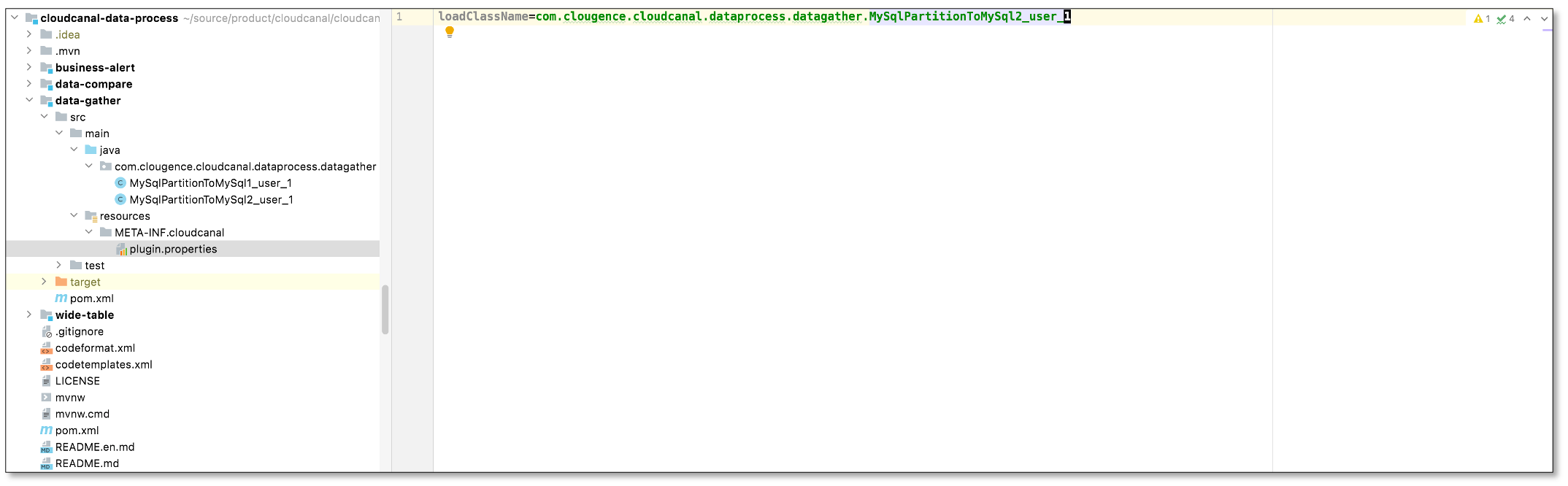
% pwd
/Users/zylicfc/source/product/cloudcanal/cloudcanal-data-process
% mvn -Dtest -DfailIfNoTests=false -Dmaven.javadoc.skip=true -
Dmaven.compile.fork=true clean package - 选择列,默认全选,选择上传代码包2
- 确认创建,并自动运行
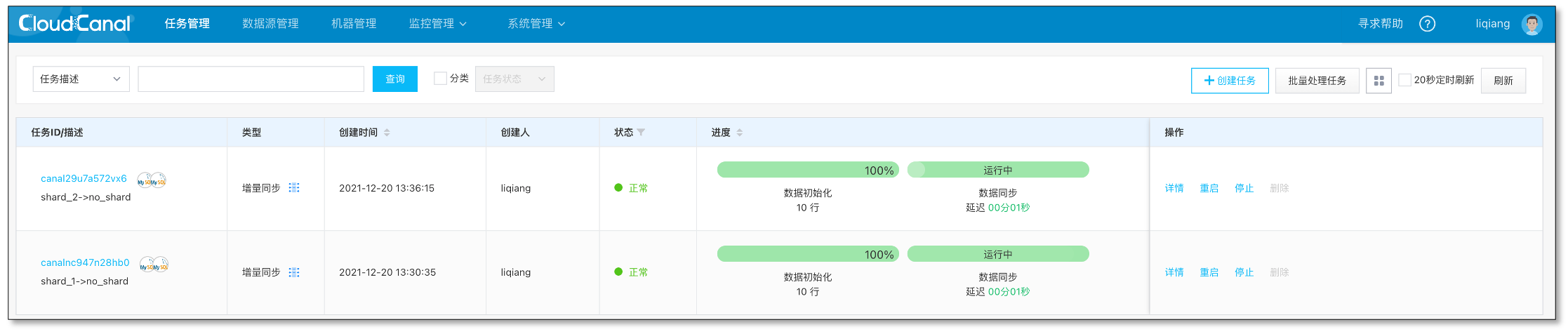
分库任务状态
- 两个分库汇聚任务正常运行
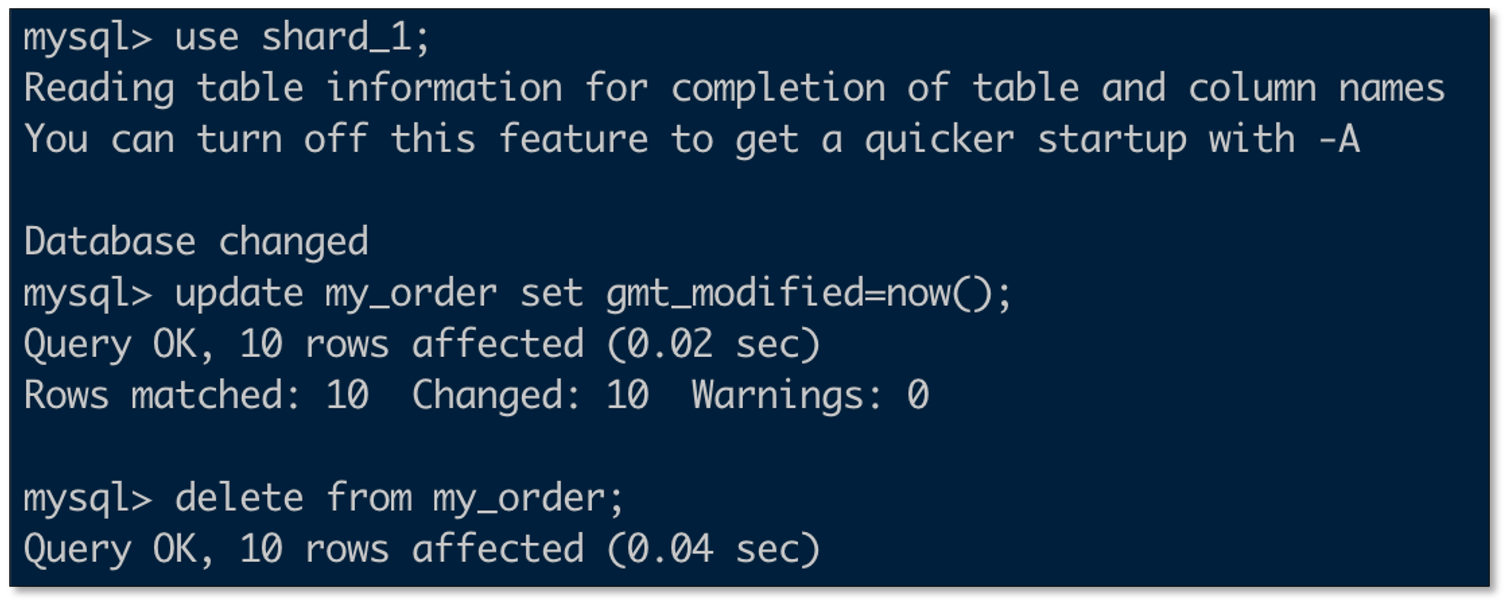
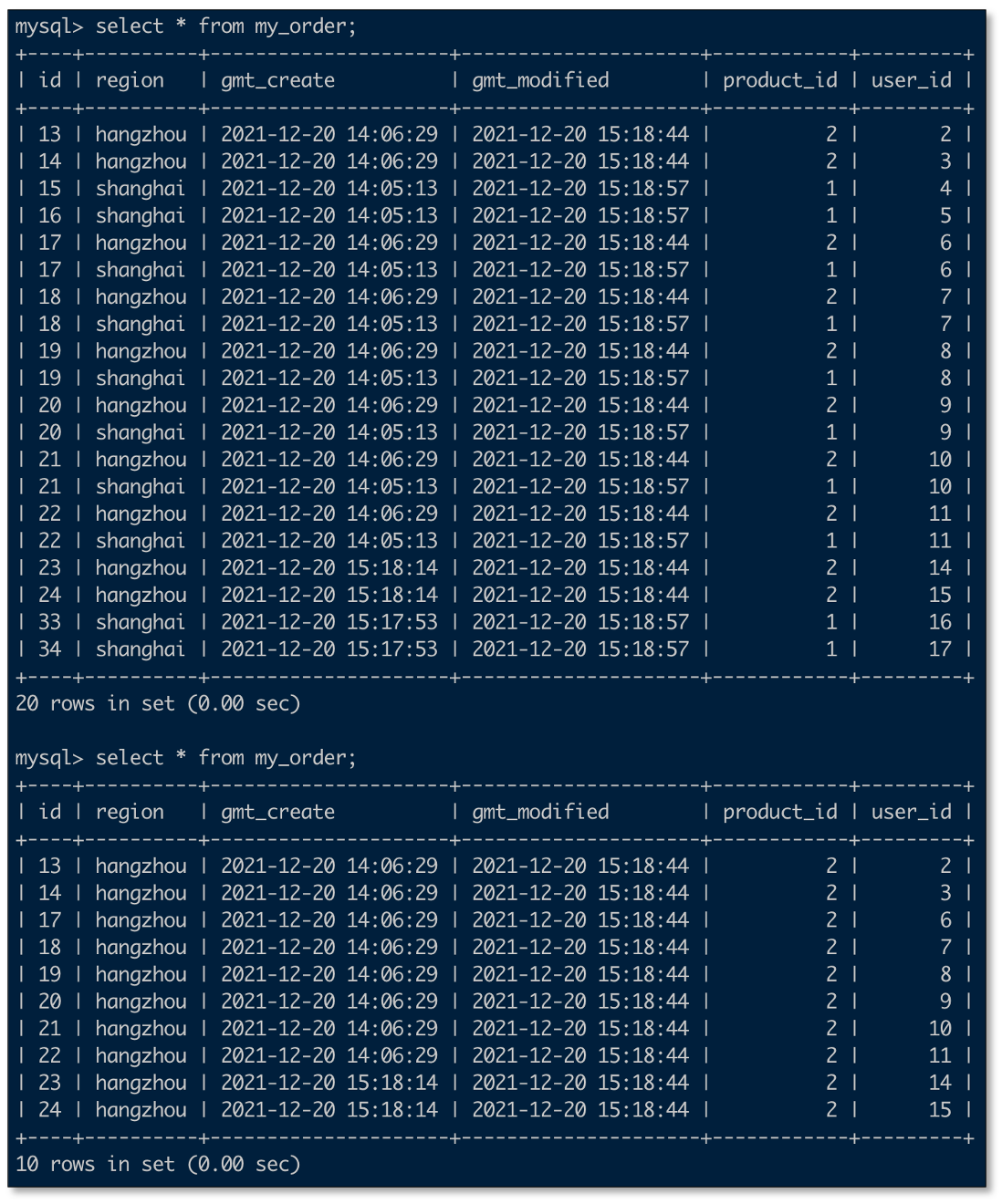
校验数据
- 变更shard_1数据
- 变更shard_2数据

- 查看no_shard汇聚库数据
常见问题
是否支持带数字后缀的分表
支持,就是在自定义代码中匹配表名会稍微复杂些,需要自行修改匹配逻辑。
是否支持异构数据库
支持,自定义代码是 CloudCanal 通用功能,可实现自由的数据变幻。但是对于具体的目标数据源,行为可能会发生一些细微变化,需要进行一定的测试和验证。
如果遇到出错或者问题怎么办?
如果会 java 开发,建议打开任务的 printCustomCodeDebugLog 观察输出的数据是否符合预期,如果不符合预期,可以打开任务的 debugMode 参数,对数据转换逻辑进行调试。
如果不会 java 开发, 找 CloudCanal 同学协助。
总结
本文简单介绍了如何使用 CloudCanal 进行分库分表数据汇聚。各位读者朋友,如果你觉得还不错,请点赞、评论加转发吧。