🎉 CloudCanal 上线 V6.1.0.0:KingbaseES 分区表迁移性能大幅提升
实时同步数据,
增量的
仅需几分钟,即可构建涵盖 60 多种数据源的端到端数据管道,轻松支撑实时分析与 AI 应用。无论您的数据位于云端还是本地,都能以低于 3 秒的超低延迟,实现极速、顺畅的数据流转。

0+客户数
0+下载和激活数
0+活跃的社区用户数
为什么选择 CloudCanal
百万行数据/月
了解更多成本对比:CloudCanal vs. Airbyte vs. Fivetran
1M 行/月
¥483
CloudCanal
(BYOC)
¥3240
Airbyte
(Cloud)
¥3600
Fivetran
(Standard)
10M 行/月
¥484
CloudCanal
(BYOC)
¥7200
Airbyte
(Cloud)
¥9720
Fivetran
(Standard)
100M 行/月
¥493
CloudCanal
(BYOC)
¥21600
Airbyte
(Cloud)
¥20880
Fivetran
(Standard)
1000M 行/月
¥583
CloudCanal
(BYOC)
¥100800
Airbyte
(Cloud)
¥86400
Fivetran
(Standard)
*: 包含一个阿里云 ECS t2.xlarge 工作节点,¥483/月
秒级同步
CloudCanal
<= 10 秒 *Airbyte
>= 1 分钟Fivetran
>= 1 分钟产品特性
CloudCanal 的关键特性
实时同步
低延迟,小于 3 秒,实时同步和更新,让数据更有价值,业务具有更多可能性。
数据安全
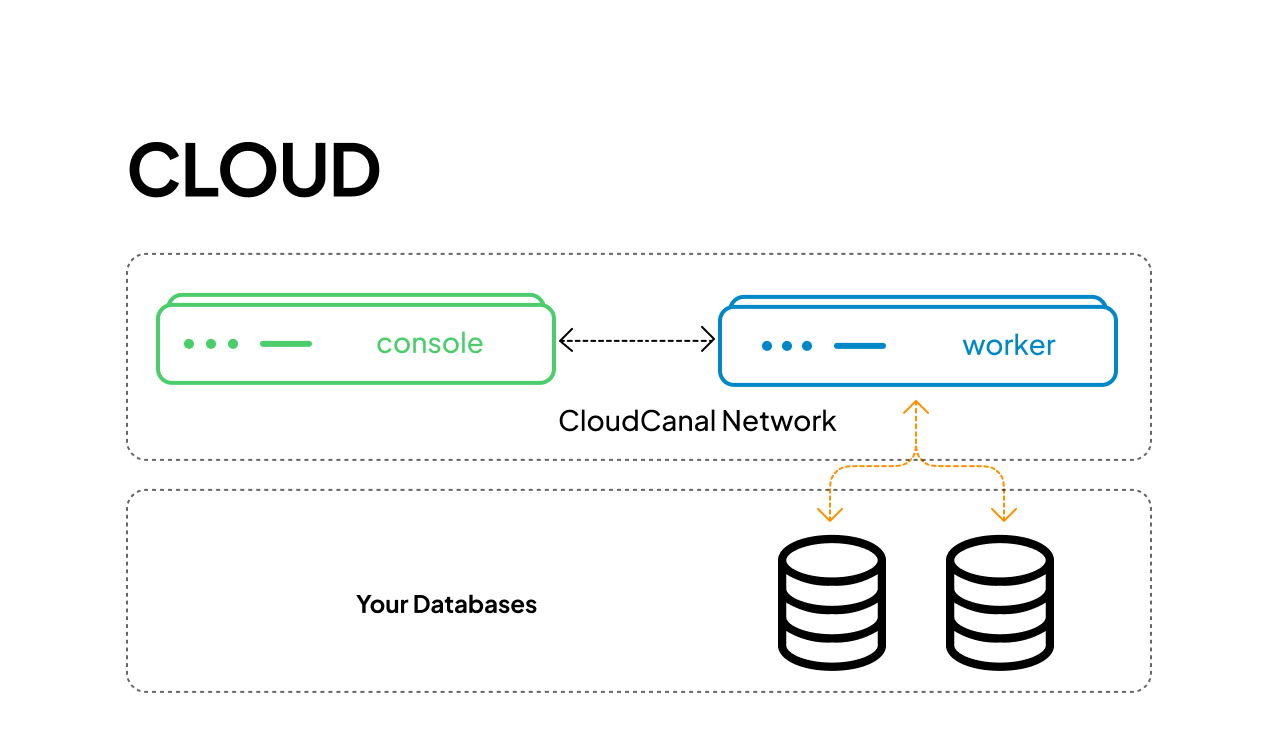
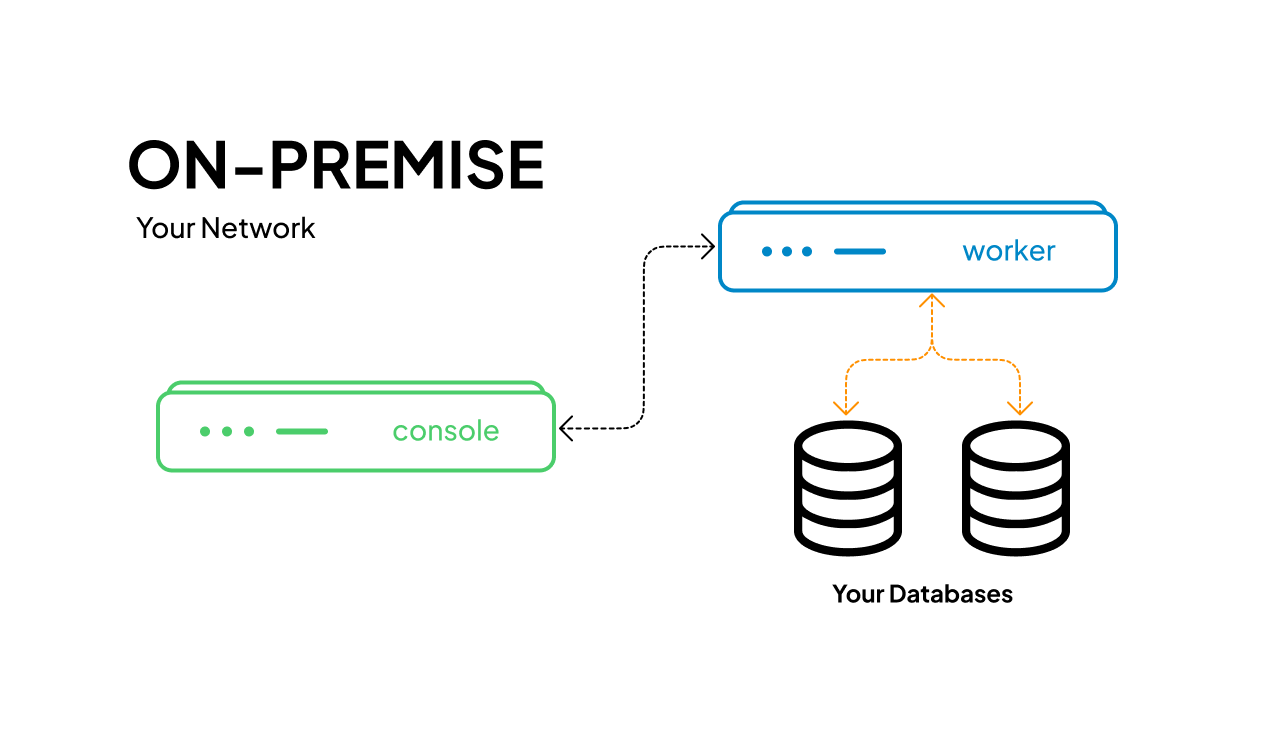
数据不出用户网络,无需连接外网,避免数据泄露风险。
可视化,自动化
操作便捷,门槛更低。自动化的任务流转减少了手动操作。
精准传输
数据高度一致,精准异构数据转化,并内置校验与订正功能。
端到端架构
结构简单,问题排查便利,低延迟,满足大部分场景。
60+ 数据源
支持主流数据库、实时仓库、消息队列、搜索引擎和缓存 — 更多数据源正在被支持中。
产品功能
丰富的功能,简单的操作
01
增量同步
全量迁移
结构迁移和同步
数据校验和订正
GenAI 服务
监控告警

增量同步
 支持大部分数据链路,秒级别延迟
支持大部分数据链路,秒级别延迟- 支持库表列等元数据映射
- 内置虚拟列、数据清洗、宽表构建、过滤条件等可视化能力
已经支持的数据源
更多的数据源正在被支持中
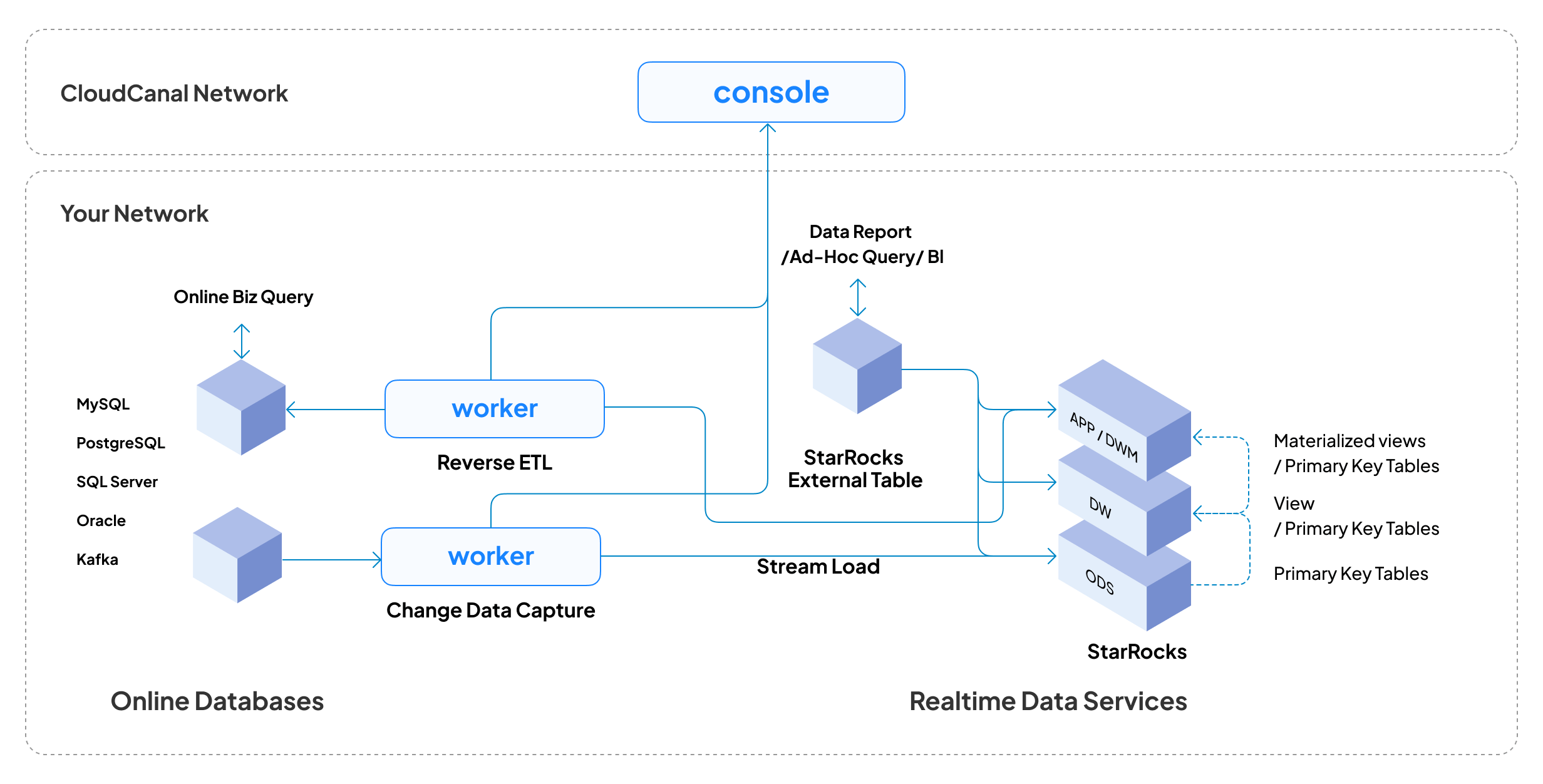
打通数据孤岛,丰富数据应用
解锁您的数据的巨大潜力。
了解更多
发现 CloudCanal 的巨大潜力

data_sync_sample
MySQL 迁移到 Snowflake 怎么做?4 种常见方案对比(不停机/准实时)
MySQL 迁移到 Snowflake 怎么选?手动导出、批量 ETL、Kafka、CDC 4 种方案一次讲清;想不停机、准实时同步,用 CloudCanal 10 分钟搭好全量+增量链路。

徐雨霞
May 15, 2026

技术分享
什么是反向 ETL?从数仓到业务系统的数据回流解读
反向 ETL(数据激活)是什么?本文详解数据从数仓回流到业务系统的概念与价值,介绍ETL常见应用场景、与 ETL/CDC 的区别,以及典型实现方式。
徐雨霞
May 13, 2026

data_sync_sample
Redshift 增量同步到 MySQL 实战(反向ETL教程)
别再手动导 CSV 了!用 CloudCanal 把 Redshift 增量一键推回 MySQL(定时扫描/增量字段/无需 CDC),从配置到上线约 10 分钟跑通。
徐雨霞
May 11, 2026
联系我们

扫码添加微信,获取技术支持