跨互联网数据同步
简介
将数据库端口暴露至公网是一种极具风险的行为,可能对数据库的安全性造成严重威胁。因此,在生产环境中通常会禁止数据库端口直接暴露至公网。然而,这种限制也为数据迁移带来了新的挑战:
如何在端口不暴露的情况下实现数据同步?
为了解决这一问题,CloudCanal 提供了一套高效且安全的解决方案。
本文将详细介绍 CloudCanal 如何实现跨互联网安全数据同步,其具有以下特点:
- 两端数据库完全不开放公网端口
- 两端数据库元数据可映射
- 基于 HTTPS 传输
- 具备用户名密码鉴权机制
- 支持多种数据库异构互通
- 不依赖消息等软件
技术点

Tunnel数据源
去掉消息依赖的跨互联网数据库互通,我们是通过一个虚拟的数据源 Tunnel 实现。
Tunnel 数据源本身并不是实体数据库,而是一组逻辑信息,包括
- ip(或域名)
- port
- 用户名
- 密码
- TLS 证书文件和密码
- 元数据
通过这个虚拟数据源,我们可以使用 HTTP(S) 或 TCP 实现数据拉取或者接收数据的目的,同时完全匹配 CloudCanal 业务模型,达到功能的完整性。
PUSH模型
对于数据传输模式 PUSH 或 PULL,我们选择了 PUSH 模式,即客户端将数据推送到服务端,本质原因在于
- 主要解决互通问题,而非订阅问题
- 目标端同步写入数据更加匹配 CloudCanal 其他目标端风格
- 数据通道无数据持久化,无需维护 store 来暂存数据
当然,PUSH 模式也带来一些问题,包括
- 如何确保最终数据写入再提交位点
- 位点回溯复杂(全量和增量、不同数据源位点格式不一致)
对于上述两个问题,我们采用 延迟提交位点技术 解决。
延迟提交位点技术
采用 PUSH 模式后,位点管理是比较复杂且危险的工作,如果提早提交位点,可能丢数据。
为此,我们实现了 延迟提交位点技术,即客户端每一次写入 server 端,只返回已经提交的位点,并且将所有数据源、所有任务类型的位点序列化成 json 字符串。
通过这项技术,我们能够确保位点之前的数据肯定已经写到对端,并且在某些业务场景下,通过客户端任�务的位点回溯,达到重复消费某一段时间数据的目的。
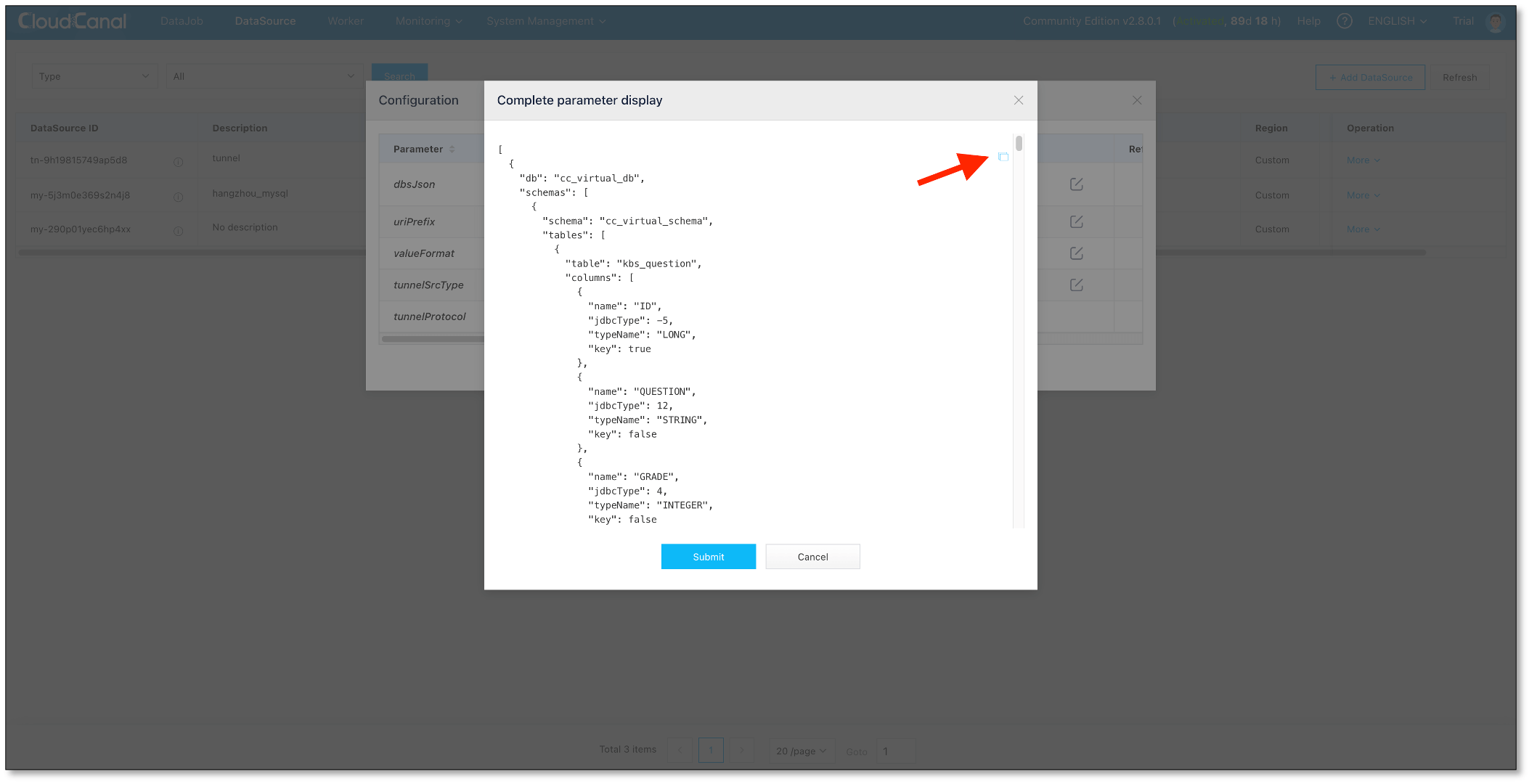
元数据映射
因为使用了虚拟的 Tunnel 数据源,并且其带有 schema(存储于CloudCanal kv配置表中), 所以针对这个数据源,我们模拟了表结构获取和迁移的过程,让其在任务创建和运维过程中如同一个真实存在的数据库。 一个真实的 Tunnel 数据源的元数据如下:
[
{
"db": "cc_virtual_db",
"schemas": [
{
"schema": "cc_virtual_schema",
"tables": [
{
"table": "WORKER_STATS",
"columns": [
{
"name": "ID",
"jdbcType": -5,
"typeName": "LONG",
"key": true
},
{
"name": "GMT_CREATE",
"jdbcType": 93,
"typeName": "TIMESTAMP",
"key": false
},
{
"name": "AUCRDT",
"jdbcType": 93,
"typeName": "TIMESTAMP",
"key": false
}
]
},
{
"table": "KBS_QUESTION",
"columns": [
{
"name": "ID",
"jdbcType": -5,
"typeName": "LONG",
"key": true
},
{
"name": "CATEGORY",
"jdbcType": 12,
"typeName": "STRING",
"key": false
}
]
}
]
}
]
}
]
我们可以通过结构迁移 (MySQL/SQLServer/Oracle -> Tunnel) 扩充它,或者直接通过 数据源管理->更多->查看配置->_**dbsJson **_进行修改。
操作示例
本示例使用阿里云资源模拟杭州 RDS for MySQL 到深圳 RDS for MySQL , 两端数据库均不开公网端口,数据走互联网, 采用 HTTPS 传输和用户名密码认证。
环境准备
-
杭州环境部署 CloudCanal ,并购买 RDS for MySQL 作为源端


-
深圳环境部署 CloudCanal , 并购买 RDS for MySQL 作为目标端


-
因 CloudCanal 为 docker 版本 ,深圳环境 CloudCanal 安装包解压后 ,需要修改 docker-compose.yml 端口映射再安装/升级,并开放 ECS 安全组相关端口,以便远程连接
-
此��例以 18443 端口作为 Tunnel 数据源监听端口


为目标端数据库初始化元数据
- 因无法通过 Tunnel 到对端数据库做结构迁移,所以需要事先使用 mysqldump 等工具初始化对端数据库结构
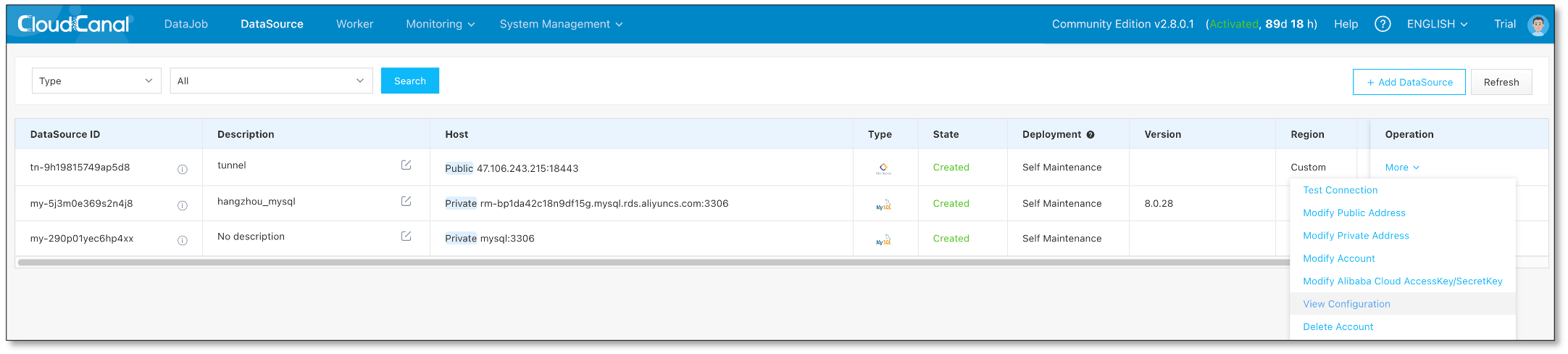
添加 Tunnel 数据源
-
分别在源端和目标端 CloudCanal 配置 Tunnel 数据源

-
源端数据源列表,源端的 Tunnel 地址应当是目标端 Tunnel 所在服务器的地址

-
目标端数据源列表

为 Tunnel 初始化元数据
-
源端创建一个 MySQL -> Tunnel 结构迁移,并完成
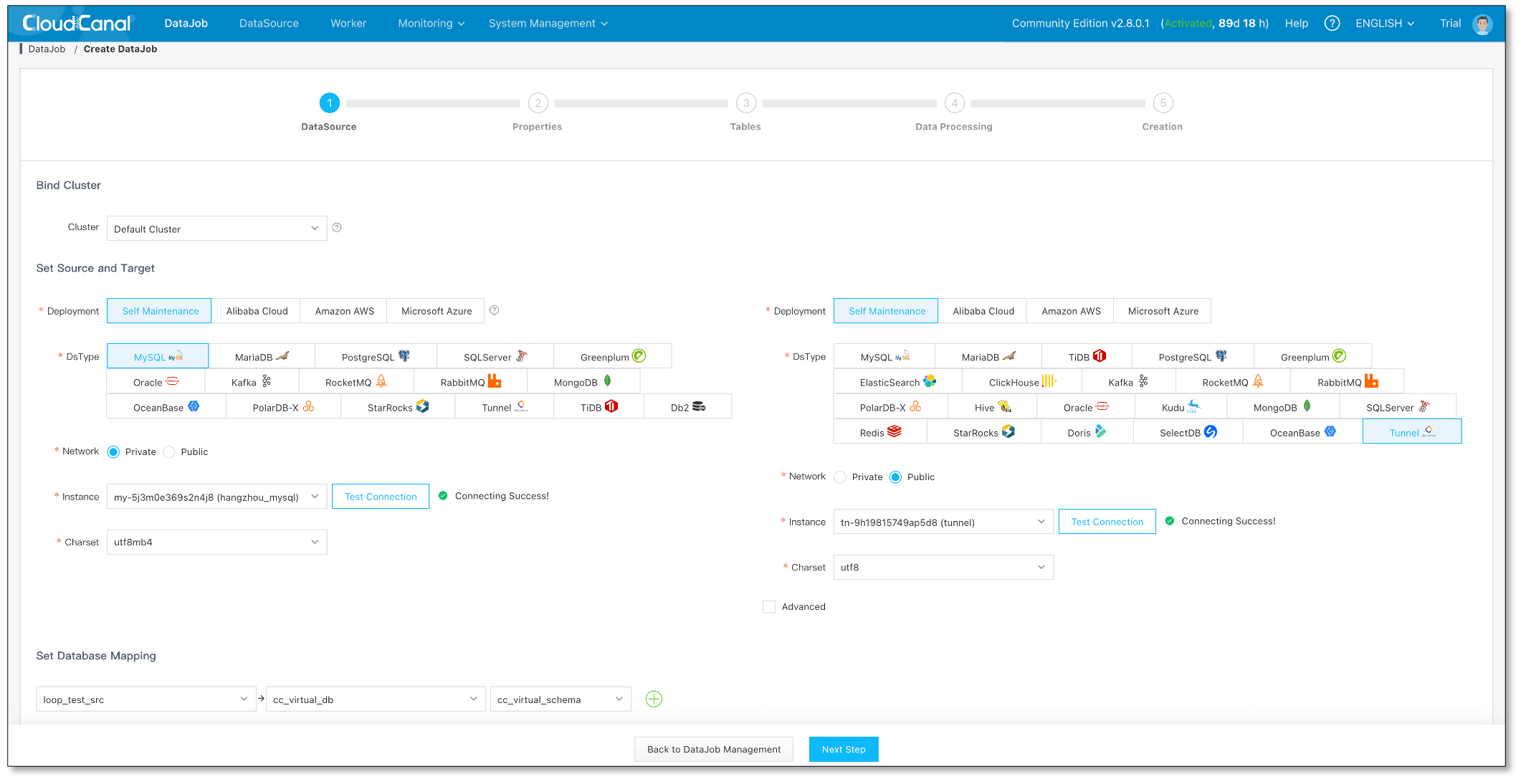

-
从源端 Tunnel 数据源拷贝结构并复制到目标端

目标端任务创建
-
选择 Tunnel 和 目标数据库

-
选择数据同步

-
选择表、列、映射略
-
任务正常运行,监听端口并准备接收数据

源端任务创建
-
选择源端数据库 和 Tunnel 数据源
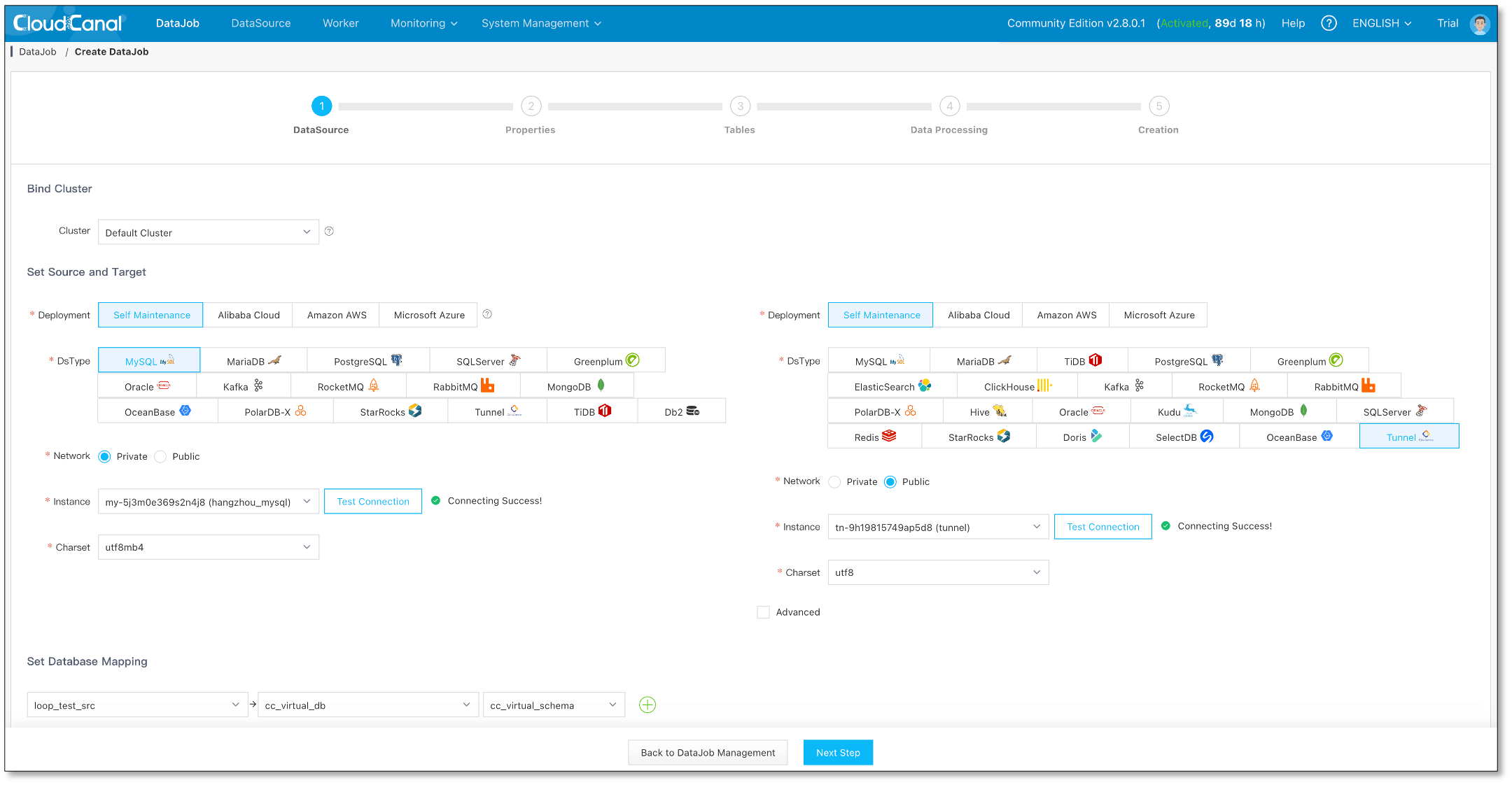
-
选择数据同步,并初始化数据

-
数据持续同步中

数据验证
造增量数据
- 为了造数据简便,开下源端数据库公网地址

数据校验
- 在深圳环境添加源端数据源,并做数据校验。结果显示数据一致。

应用场景
跨云数据同步
通常情况下,不同云厂商的服务器之间,或同一云厂商下不同地域的服务器,无法通过内网直接实现数据同步。
一种常见且有效的方案是将数据传输至可访问公网的服务器,并利用第三方工具完成数据迁移。然而,工具的效率与安全性往往决定了这个方案是否可靠。
借助 CloudCanal 的 Tunnel 数据源,可以安全且高效的实现这个解决方案,简化跨云或跨地域的数据迁移:
- 在源端与目标端所在的内网中分别部署一台装有 CloudCanal 的服务器并暴露至公网。
- CloudCanal 服务器与数据库之间通过 VPC 等方式在内网连接。
- 依照 操作实例 中的步骤着手创建数据同步任务
常见问题
-
目前支持哪些链路的互通?
- MySQL/SQLServer/ORACLE -> MySQL , 其他互通按需添加。
-
Tunnel 到对端数据库能做结构迁移么?准备表结构比较麻烦
- 因为数据库结构对元数据精度要求很高,Tunnel中间结构主要为同步服务,所以元数据级别上还无法构成精确的结构迁移源端。建议构建临时实例(��只dump表结构)并开公网,再使用CloudCanal结构迁移解决问题。
-
Tunnel 数据源有结构,能动态编辑么?
- Tunnel 数据源模拟了一个数据库,编辑任务能力天然具备。加表先编辑目标端任务,再编辑源端任务,否则反之。我们后续计划用一篇专门的文章介绍这个运维操作。
-
目前数据互通还存在什么问题?
- 对于 blob 等字段类型还需要进一步支持和验证
- 跨互联网,性能层面需要经过特别的优化
- 安全层面,目前仅用到 HTTPS 证书加密,配合自定义的账号密码
总结
本文主要介绍纯粹通过 CloudCanal 进行数据互通实践,通过引入虚拟数据源,达成数据互通和元数据映射等能力,具备不错的可落地性。
