使用大模型将数据嵌入到 PostgreSQL 向量
简述
本文是 CloudCanal 构建 RAG (Retrieval-Augmented Generation,检索增强生成) 应用系列文章:
- 使用大模型将数据嵌入到 PostgreSQL 向量
- 基于 PostgreSQL 向量构建 RAG API 服务
本文主要介绍使用 CloudCanal 全量迁移,通过大模型嵌入能力,将文档向量化后写入到 PostgreSQL vector 中,为 RAG 能力做前置工作。
为什么需要 RAG?
尽管 GPT-4 等大型语言模型(LLM)具备强大的理解和生成能力,但在企业级应用中仍存在以下局限:
- 无法访问私有知识库:无法回答企业专属内容,例如内部文档、业务规则等。
- 易出现幻觉:可能生成看似合理但与事实不符的回答。
- 上下文泛化严重:缺乏个性化上下文,内容不够精准。
- 知识更新滞后:内容来源固定于训练数据,难以保持最新状态。
RAG(Retrieval-Augmented Generation) 将 文档检索 与 语言模型推理 相结合,用户可以将私有知识实时注入大模型,使其具备以下优势:
- 更高的准确性
- 更强的个性化
- 实时可控的知识更新能力
为什么需要数据向量化?
RAG 的本质是“检索 + 生成”。其中,高质量的语义检索 是基础。为了让机器理解用户问题的含义,并从大量内容中找出相关文本,就需要把文本转化为便于计算语义相似度的格式 —— 向量 (Embedding)。
向量化的意义在于:
- 将文本(如段落、句子)表示为多维数字数组,映射到语义空间
- 相似内容在向量空间中更接近,便于高效检索
- 是让机器“理解”人类语言的关键一步
因此,数据向量化是 RAG 的第一步,也是决定检索效果和生成质量的基础能力。
CloudCanal 数据向量化的优势
相比于传统方案,CloudCanal 提供的数据向量化能力具备以下优势:
- 零代码、零命令行,上手即用
- 多种数据源支持:支持 Markdown、TXT、本地文件、数据库(如 PostgreSQL)、对象存储(如 OSS、S3)等多种内容来源
- 大模型平台灵活切换:可快速切换调用不同模型 API,评估嵌入质量
RagApi 工作流程
CloudCanal 构建的 RagApi 服务需要通过两个任务实现。本文主要介绍 任务一(文件向量化) 的操作步骤。
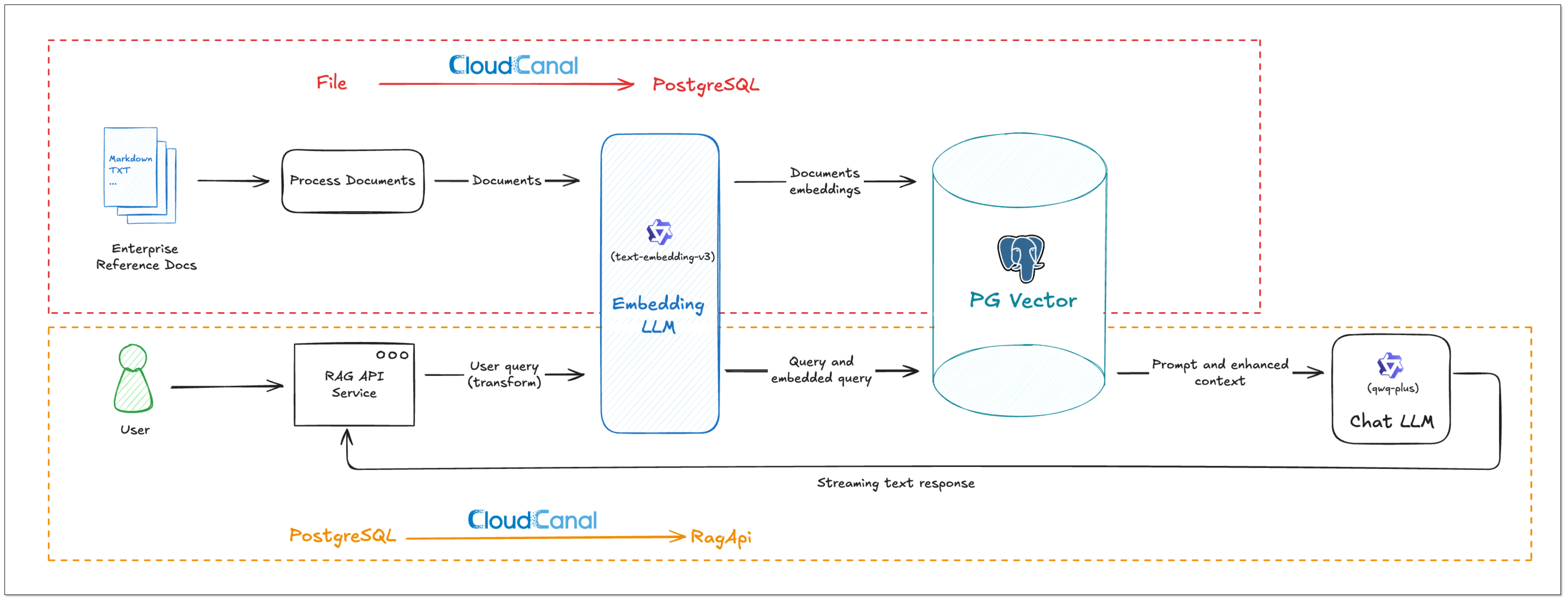
任务一:数据准备与嵌入(File → PostgreSQL 向量库)
-
数据采集与准备
企业知识来源包括 Markdown、TXT、数据库、内部文档等。用户通过 CloudCanal 创建嵌入任务,配置数据源、模型、目标表等信息。 -
数据切分与向量化
CloudCanal 自动处理原始文档并生成向量嵌入,写入 pgvector 扩展的向量字段中(如__vector列)。
任务二:API 构建与服务发布(PostgreSQL → RagApi)
关于该任务的详细内容,可阅读 基于 PostgreSQL 向量构建 RAG API 服务。
支持的大模型
CloudCanal 使用 Embedding 模型对数据进行向量化,目前支持的嵌入模型如下:
| 平台 | 模型 |
|---|---|
| 阿里云百炼(DashScope) | text-embedding-v3 text-embedding-v2 text-embedding-v1 |
| Cohere | embed-english-v2.0 |
| HuggingFace | sentence-transformers/all-MiniLM-L6-v2 |
| OpenAI | text-embedding-3-large text-embedding-3-large text-embedding-3-small |
| LocalAI | text-embedding-ada-002 |
操作步骤
CloudCanal 当前支持 SshFile、OssFile、S3File 3 种文件类型数据源。
本例将演示如何基于以下环境,通过 CloudCanal 将文件向量化并存储到 PostgreSQL 向量数据库。
- 向量数据源:自建 PostgreSQL
- 文件数据源:SshFile
- 嵌入模型:阿里云百炼平台(DashScope)的 text-embedding-v3
下载 CloudCanal
下载安装 CloudCanal 私有部署版本。
准备数据源
- 登录 阿里云百炼 并创建 API-KEY。
- 本地安装免费的 PostgreSQL 数据库。
#!/bin/bash
# 创建 docker-compose.yml 文件
cat <<EOF > docker-compose.yml
version: "3"
services:
db:
container_name: pgvector-db
hostname: 127.0.0.1
image: pgvector/pgvector:pg16
ports:
- 5432:5432
restart: always
environment:
- POSTGRES_DB=api
- POSTGRES_USER=root
- POSTGRES_PASSWORD=123456
volumes:
- ./init.sql:/docker-entrypoint-initdb.d/init.sql
EOF
# 自动执行 docker-compose 启动
docker-compose up --build
# 进入 PG 命令行
docker exec -it pgvector-db psql -U root -d api
- 创建高权限账号并登录。
- 切换到需要建表的目标 schema (如
public)。 - 执行以下 SQL 开启向量能力。
CREATE EXTENSION IF NOT EXISTS vector;
添加数据源
登录 CloudCanal 平台,点击 数据源管理 > 新增数据源。
添加文件:
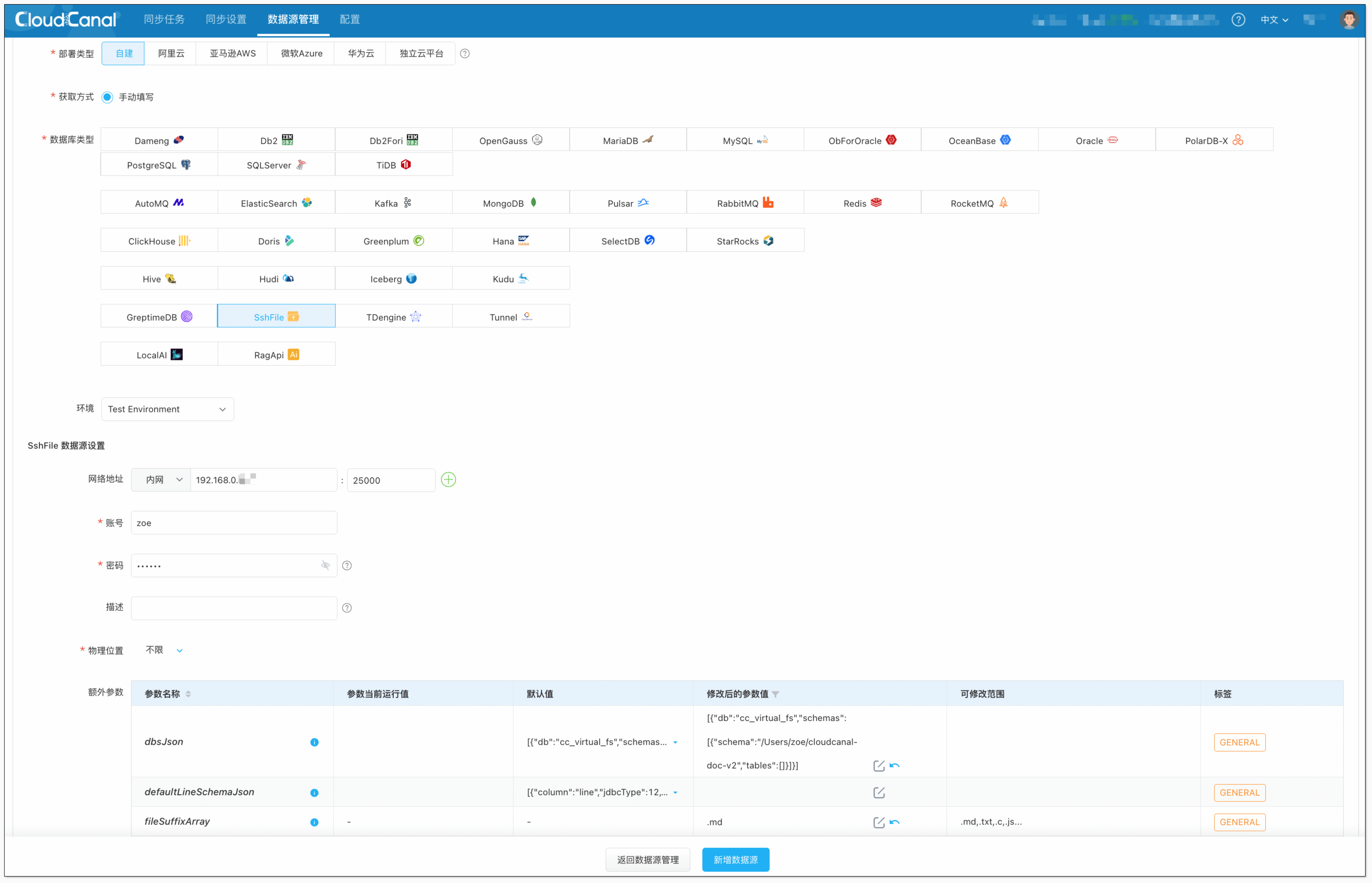
选择 自建 > SshFile 数据源,可设定额外参数。本例以 CloudCanal 文档为例:
- 网络地址:填写目标文件所在机器和 SSH 端口(默认22)。
- 账号密码:即登录目标机器的用户名、密码。
- 参数 fileSuffixArray:填写
.md以过滤出所有 markdown 文件。 - 参数 dbsJson:复制默认值并修改 schema 值(即目标文件所在根目录)。
[
{
"db":"cc_virtual_fs",
"schemas":[
{
"schema":"/Users/johnli/source/cloudcanal-doc-v2",
"tables":[]
}
]
}
]
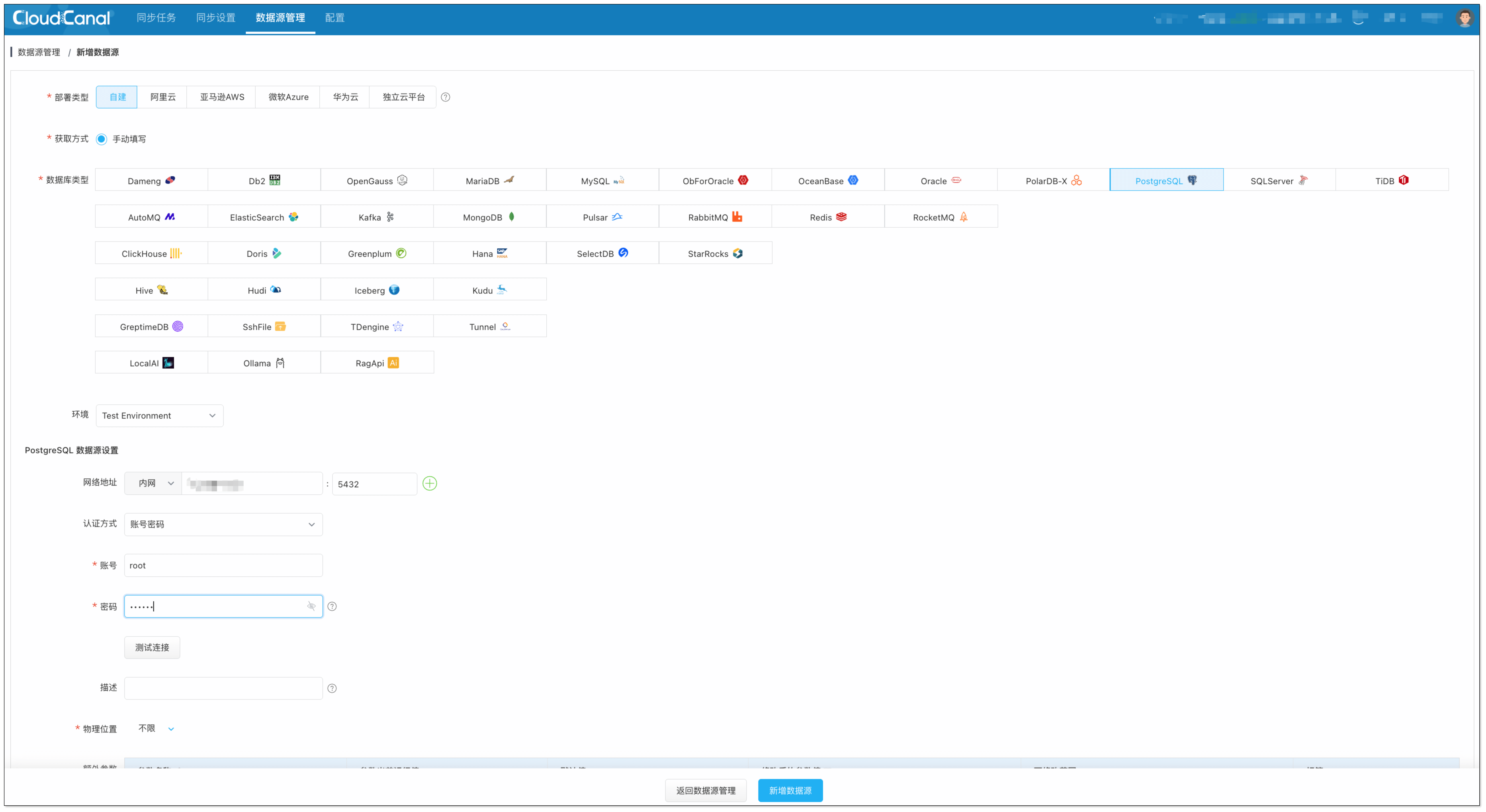
添加向量数据库:
选择 自建 > PostgreSQL,获取数据源并添加。
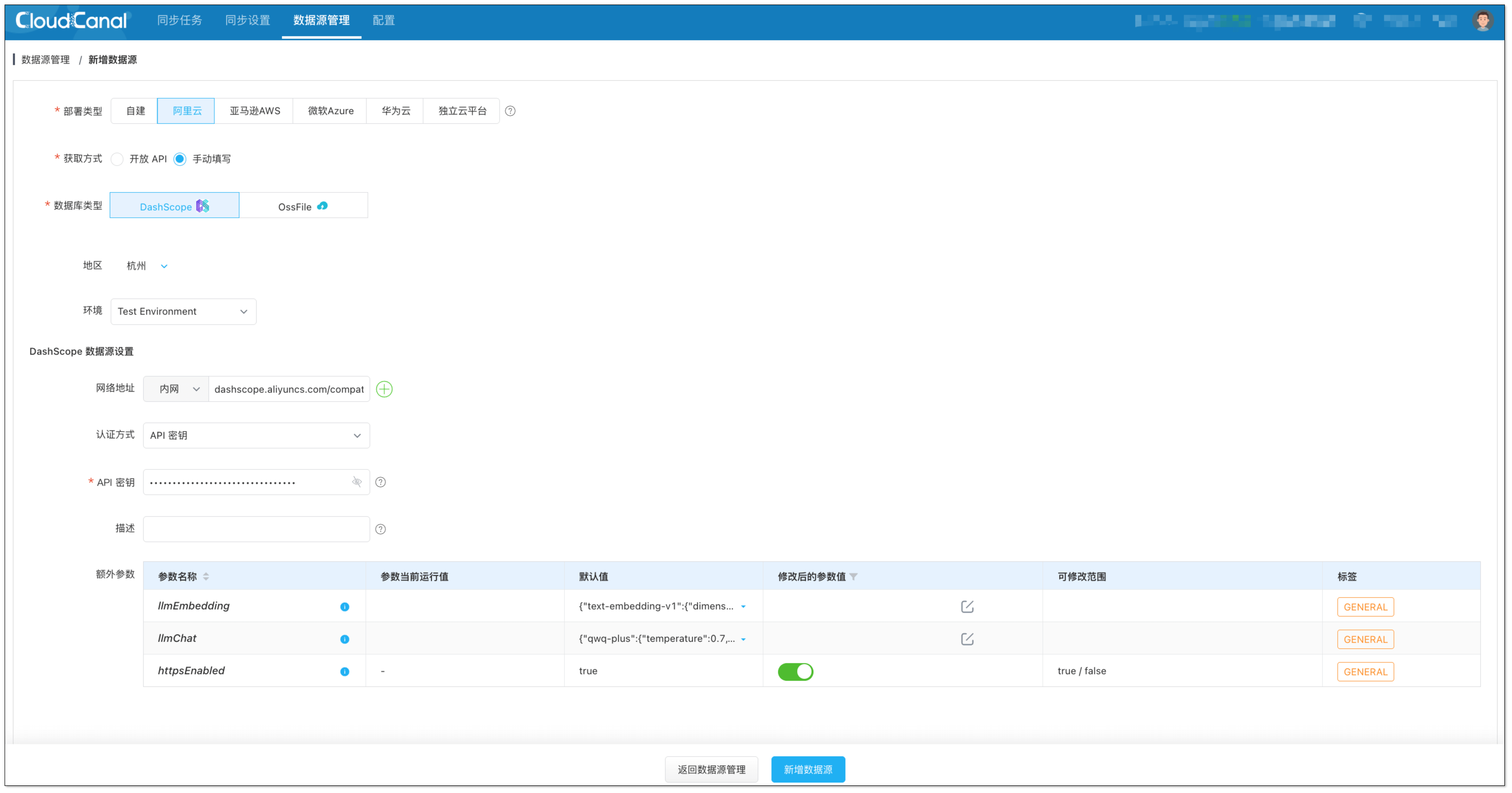
添加大模型:
选择 阿里云 > 手动填写 > DashScope 数据源,填写之前步骤获取的 API-KEY。
创建任务
-
点击 同步任务 > 创建任务。
-
选择以下数据源,并点击 测试连接 确认网络与权限正常。
- 源端:SshFile
- 目标端:PostgreSQL
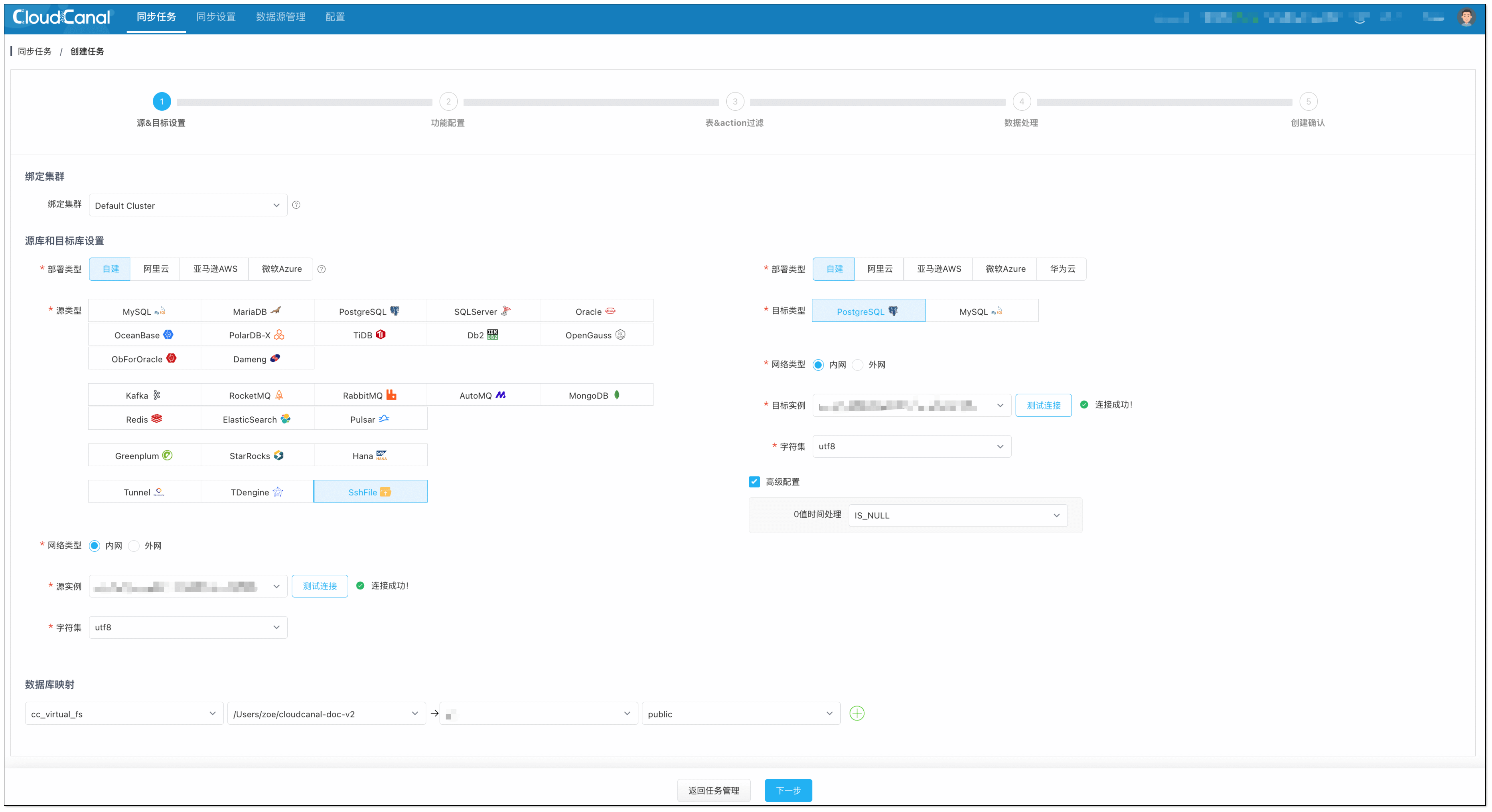
如遇到测试连接长时间不返回,可以刷新页面重新选择。
数据库连接信息错误或网络不通都可能造成该现象。
-
在 功能配置 页面,任务类型选择 任务类型选择 全量迁移,任务规格选择默认 2 GB 即可。
-
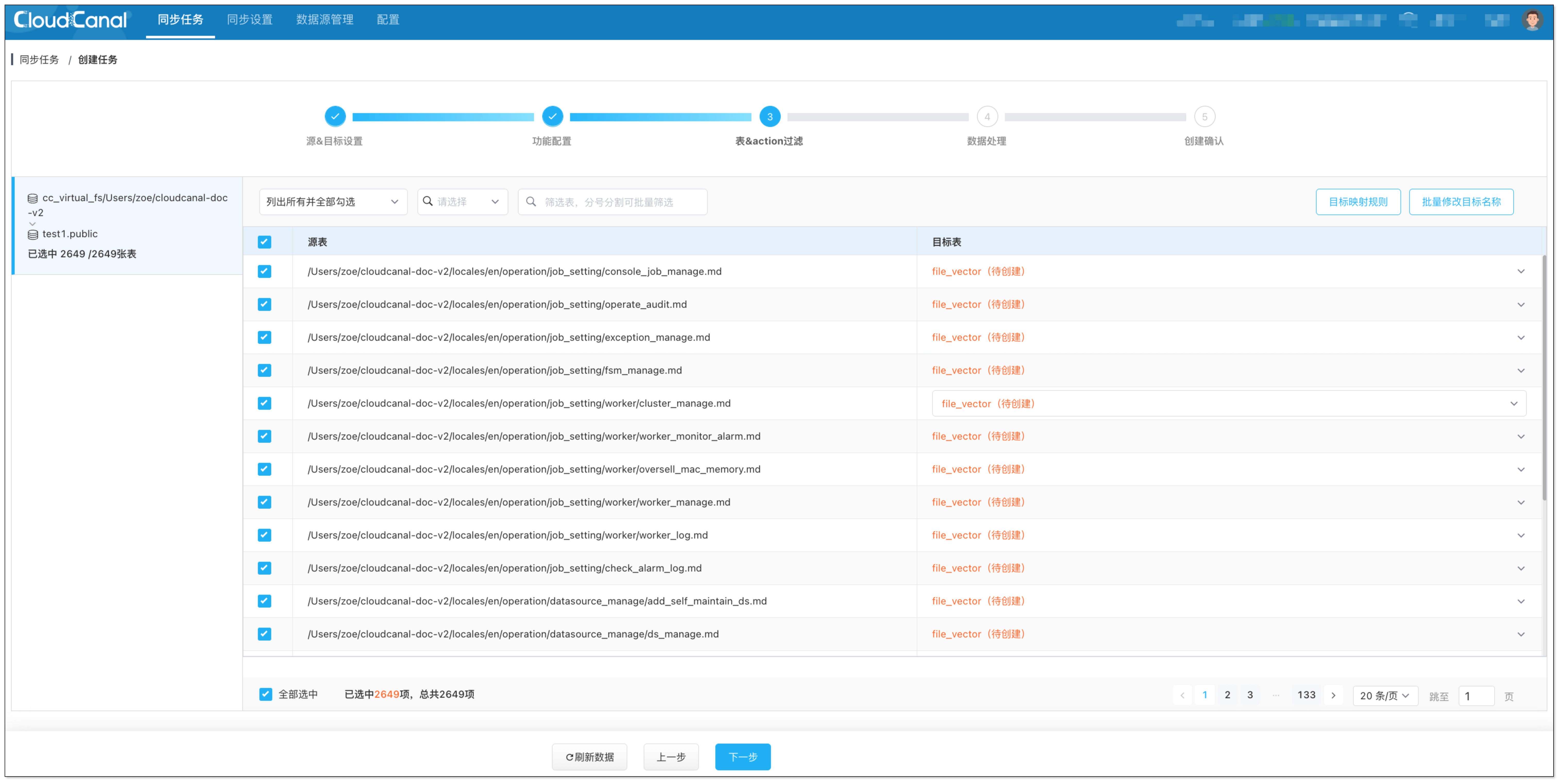
在 表&action过滤 页面,进行以下配置:
- 选择需要定时数据迁移的文件,可同时选择多个。
- 点击 批量修改目标名称 > 统一表名 > 填写表名(如
file_vector),并确认,方便将不同文件向量化并写入同一个表。
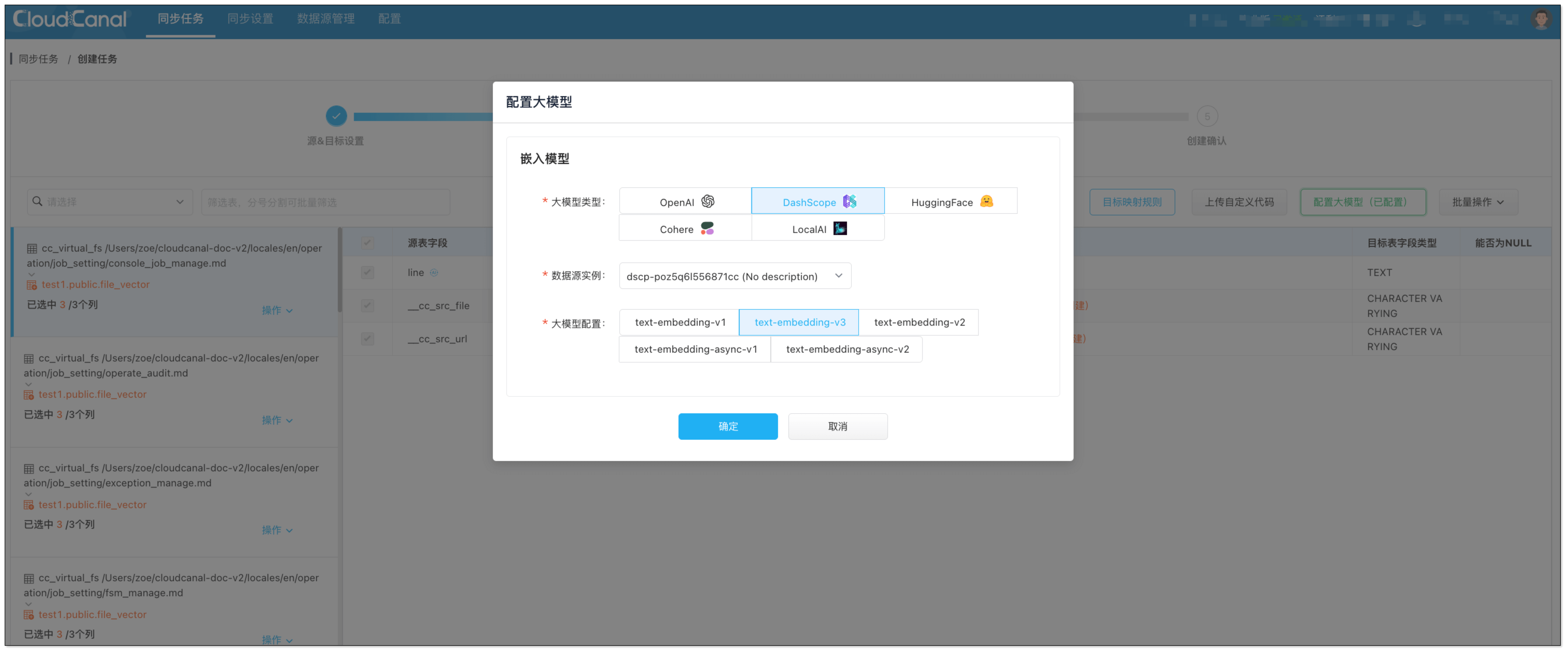
 5. 在 数据处理 页面,进行以下配置:
5. 在 数据处理 页面,进行以下配置:
- 点击 配置大模型 > DashScope > 选择刚添加的大模型实例 > 选择某一个嵌入模型(如 text-embedding-v3)。
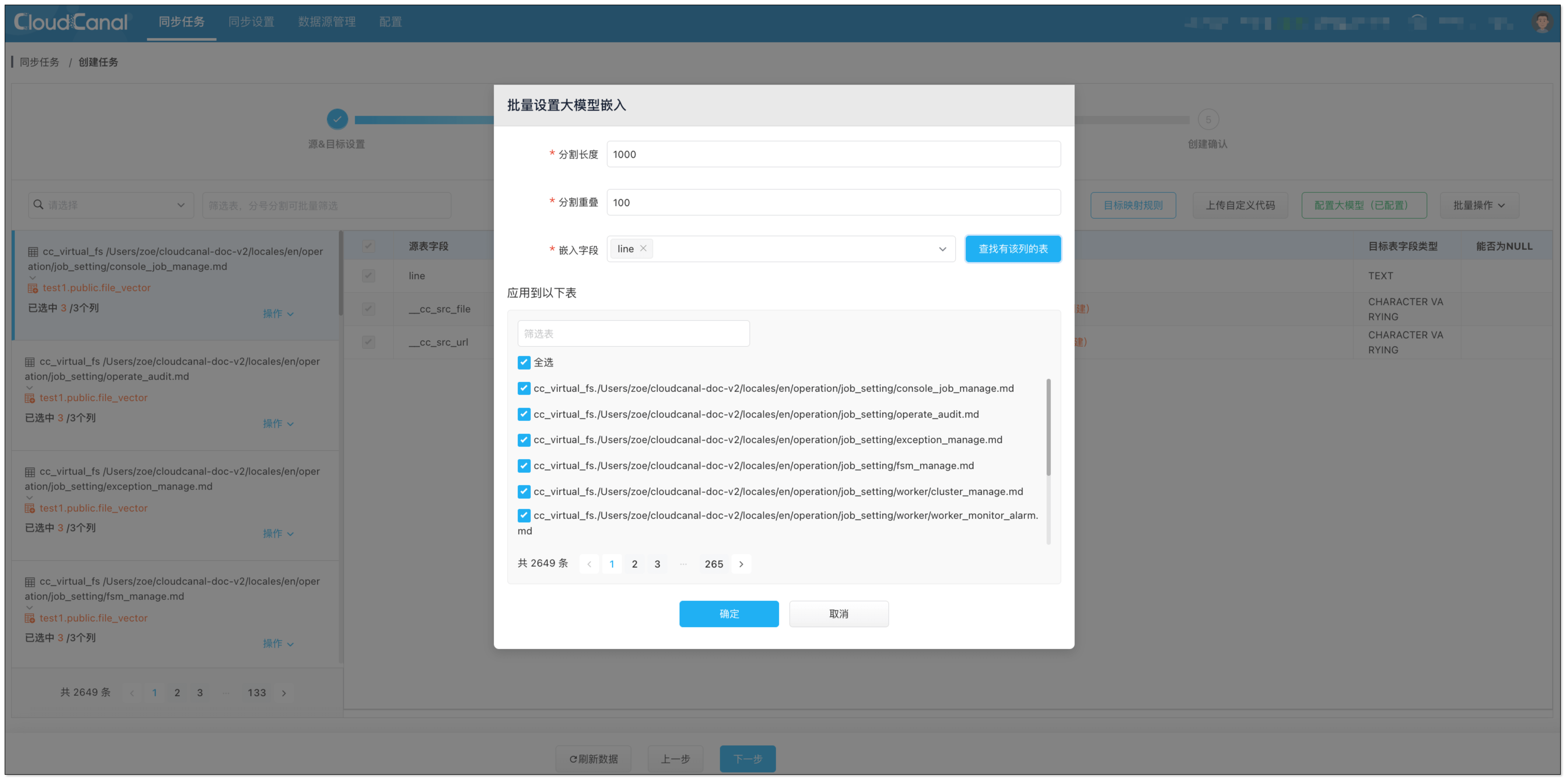
- 点击 批量操作 > 大模型嵌入,选择需要嵌入的字段,并全选表。
 6. 在 创建确认 页面,�点击 创建任务,开始运行。
6. 在 创建确认 页面,�点击 创建任务,开始运行。

验证效果
本文使用代码验证效果,也可 结合 CloudCanal RAG API 直接查询或推理。
- 使用大模型对问题进行向量化。
如问题为CloudCanal 增量同步任务延迟是什么原因?应该怎么处理?,通过相同的嵌入模型对其进行向量化。
[-0.03169125, 0.02366958, ..., -6.437579E-4, 0.03856428]
- 执行 SQL 语句获取上下文和对应的原始文件。
SELECT (2 - (__vector <=> '[-0.03169125, 0.02366958, ..., -6.437579E-4, 0.03856428]')) / 2 AS score, __content,__cc_src_file
FROM public.file_vector WHERE round(cast(float8 (__vector <=> '[-0.03169125, 0.02366958, ..., -6.437579E-4, 0.03856428]') as numeric), 8) <= round(2 - 2 * 0.6, 8)
ORDER BY __vector <=> '[-0.03169125, 0.02366958, ..., -6.437579E-4, 0.03856428]' LIMIT 10
输出结果,此处只打印 __cc_src_file 字段,且按照相关性分数由高到低返回前 10 条记录。
/Users/johnli/source/cloudcanal-doc-v2/docs/faq/solve_incre_task_delay.md:0.95078015
/Users/johnli/source/cloudcanal-doc-v2/docs/blog/tech_share/016_hana_change_data_capture_optimize.md:0.89463025
/Users/johnli/source/cloudcanal-doc-v2/docs/bestPractice/time_schedule_full.md:0.8841969
/Users/johnli/source/cloudcanal-doc-v2/docs/blog/data_sync_sample/031_biz_ob_sub.md:0.87750447
/Users/johnli/source/cloudcanal-doc-v2/docs/faq/performance_optimization.md:0.87465495
/Users/johnli/source/cloudcanal-doc-v2/docs/blog/data_sync_sample/043_redis_redis_sync.md:0.8742793
/Users/johnli/source/cloudcanal-doc-v2/docs/operation/job_manage/create_job/create_full_incre_task.md:0.8737336
/Users/johnli/source/cloudcanal-doc-v2/docs/blog/tech_share/012_hana_change_data_capture.md:0.87199974
/Users/johnli/source/cloudcanal-doc-v2/docs/blog/tech_share/012_hana_change_data_capture.md:0.86868525
/Users/johnli/source/cloudcanal-doc-v2/docs/blog/data_sync_sample/018_oceanbase_source_sync.md:0.86807317
- 使用返回的
__content进行拼接组合成上下文,结合 Chat 模型完成推理(此案例使用阿里云 qwq_plus 模型)。
增量同步延迟高的原因包括任务报错、源端无变更或心跳、目标写入性能不足、源端拉取数据慢。
处理方法:
1.检查异常监控和日志排除任务错误;
2.若源端无增量则开启心跳或确认业务流量;
3.流量大时调优参数(如减半ringBuffer和batchSize,加倍writeParallel);
4.Hana任务需确保增量表结构自动演进并检查版本兼容性;
5.网络或源端压力问题需优化基础设施。
FAQ
Q:什么是 RAG(检索增强生成)?
A: RAG 是一种结合大型语言模型(LLM)与外部知识库的技术,用于生成更准确、上下文相关的 AI 回答。
Q:RAG 有哪些优势?
A: 它解决了 LLM 生成幻觉、缺乏实时信息、无法访问私有数据等问题,提供更可信、更实用的输出。
Q:RAG 的核心流程有哪些?
A: 包括数据收集、切分、嵌入生成、向量检索、Prompt 构造与模型推理等步骤。
Q:能否使用非 OpenAI 的模型?
A: 可以。CloudCanal RagApi 支持如 DashScope、DeepSeek、LocalAI 等多种模型平台。
Q:与传统搜索有何区别?
A: RAG 不仅检索文档,还能基于上下文生成更具语义理解的自然语言回答。
总结
本文主要介绍使用 CloudCanal 全量迁移,通过大模型嵌入能力,将文档向量化后写入到 PostgreSQL 向量中,为业务构建 RAG 应用打下坚实基础。
